Small kiwis and poisonous mushrooms (#18 of 2024)
Let us continue with last week's article. I really liked the trick used in the Apple paper we mentioned to demonstrate the problems language models face with reasoning, and I have been modifying it and testing it with different models. However, my goal is not to investigate reasoning itself, but to explore the other aspect we mentioned: understanding.
In case you do not have time to read to the end, I will give away the conclusions of these tests in advance. The experiments we are about to describe show how: (1) LLMs possess an understanding of natural language that affects their competence in the reasoning they perform, and (2) the larger the LLM, the more abstract that understanding turns out to be.
I am not discovering anything new. That LLMs can be configured through natural language in order to improve their performance is something we have known since the early days of chatbots, when Sydney's prompts were leaked. And that increasing the size of an LLM increases its abstraction capacity is something we have discussed many times when mentioning the scaling hypothesis. But in this article I am going to offer simple examples that will help us understand these ideas better.
Thank you for reading me!

A small kiwi is still a kiwi
Let us begin by explaining the trap Apple researchers set for LLMs. They analyze it in detail in their paper, where they explain how it is enough to add some apparently irrelevant fact to the statement of an elementary-school problem in order to confuse the LLM and make it fail.
First, let us look at the problem statement without the trick. It is simple, but it requires a bit of reasoning:
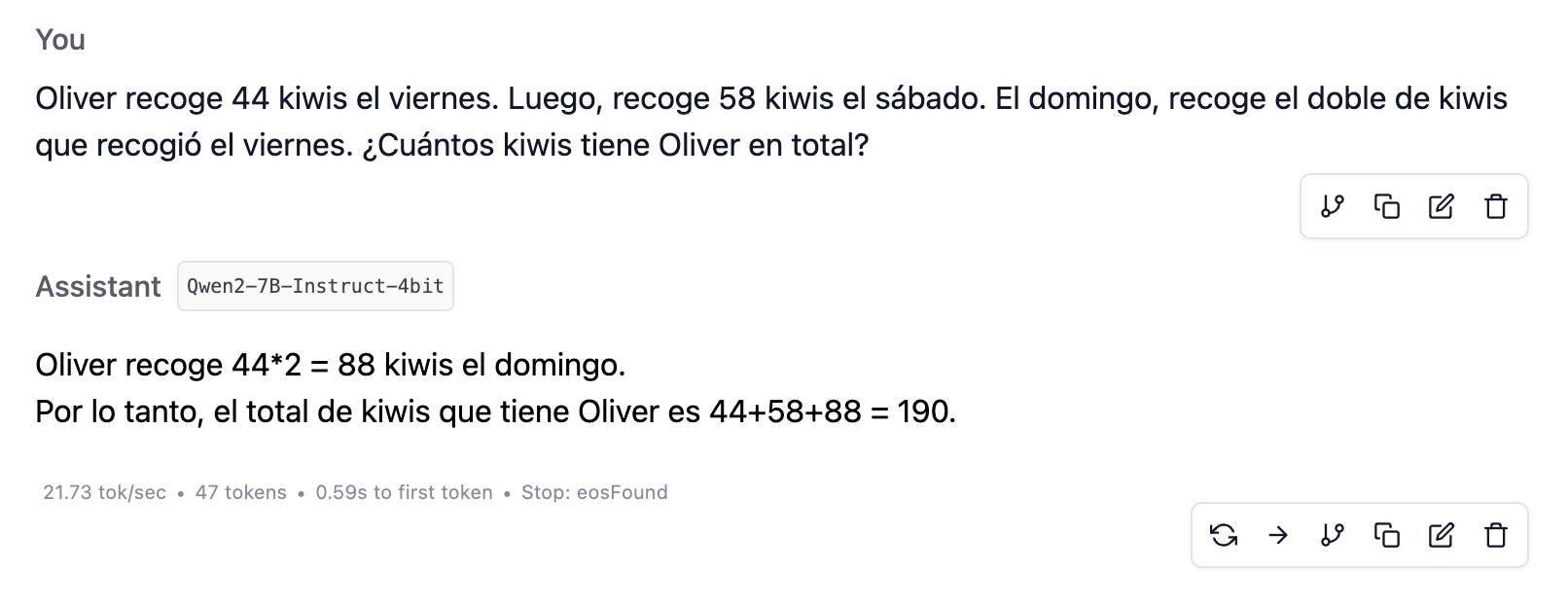
Oliver picks 44 kiwis on Friday. Then he picks 58 kiwis on Saturday. On Sunday, he picks twice as many kiwis as he picked on Friday. How many kiwis does Oliver have in total?
I downloaded LM Studio onto my MacBook Air, an M3 with 16 GB of RAM, and tested the small models Qwen2-7B-Instruct-4bit and Meta-Llama-3.1-8B-Instruct-4bit . Both solve it without difficulty, as shown in the image.
It might seem that the models are reasoning, but the authors show that this is not really the case by means of a very clever trick. They add an irrelevant fact to the statement, specifically the following sentence, the added sentence is in bold:
Oliver picks 44 kiwis on Friday. Then he picks 58 kiwis on Saturday. On Sunday, he picks twice as many kiwis as he picked on Friday, but five of them were smaller than average. How many kiwis does Oliver have in total?
The mention that five of the kiwis are smaller is irrelevant. Those kiwis should still count the same, and Oliver should still have 190 kiwis in total. However, these basic LLMs get confused and subtract them. Below is the image for Llama-3.1-8B.
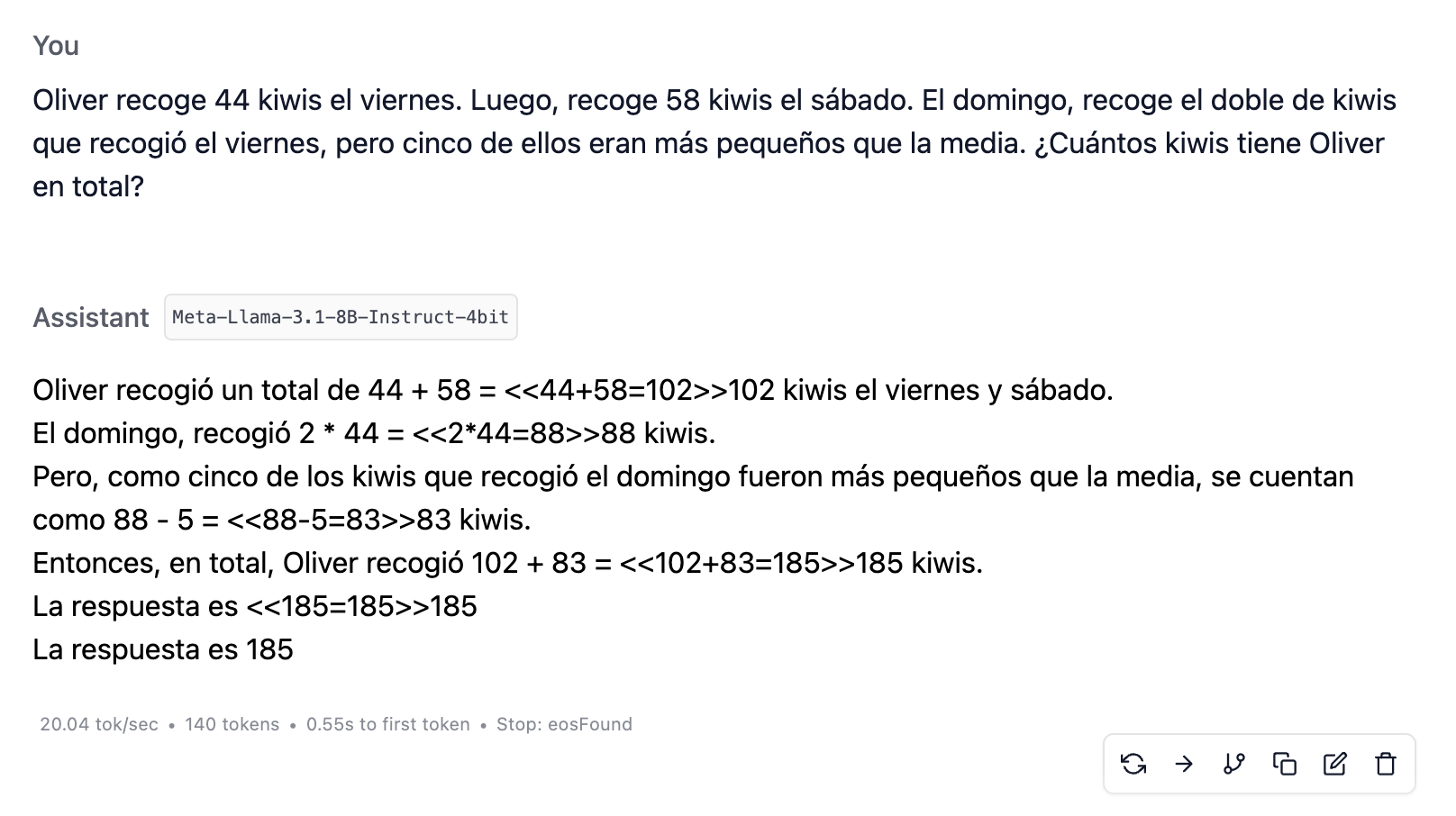
Why do they get confused? Because they apply literally a pattern they have learned: when they encounter a phrase of the form “but blah blah blah,” they tend to subtract the items mentioned in the “blah blah blah.” They do not realize that it is irrelevant that five kiwis are smaller.
Small models are inflexible
In Melanie Mitchell's article, which I also mentioned last week, there was a link to a tweet suggesting that another possible explanation for the LLM failures was a lack of sufficient context. It may be that LLMs, trained for conversation, get confused because they interpret that, for example, Oliver does not like small kiwis. We should explain to the LLM that this is a math exercise. The tweet says:
My conjecture is that, for example, with some prompt engineering telling the LLM this is a math exam, probably most of these issues would disappear.
Well, that is not the case, at least not with these small models. No matter how much explanation I add, I cannot get the small models to stop getting confused. I tried several introductions to the problem, such as the following:
-
“Solve the following math problem.”
-
“Suppose you are in math class and the teacher gives you the following problem.”
-
“Suppose you are in math class and the teacher gives you the following problem. It is a rather fussy teacher who sometimes puts tricks into the problem statement.”
Even explicitly telling them that they must not get distracted by irrelevant details, I do not get good results:
-
“Suppose you are in math class and the teacher gives you the following problem. You must add all the kiwis, regardless of their size.”
-
“You must add all the kiwis, do not subtract the ones that are smaller than normal.”
-
“You must add ALL the kiwis. YOU MUST NOT SUBTRACT the ones that are smaller than normal.”
The last instruction is the most direct possible, with uppercase phrases to emphasize their importance, and even so they still do not work properly:

When you see this, you realize how much faith the OpenAI researchers must have had in order not to become discouraged by the early models.
Large models do not get confused so easily
Let us now try with much larger LLMs: ChatGPT 4o and 4o mini. I am leaving out the o1 model because it is not a pure LLM.
The small models above have 8 billion parameters, 8B. OpenAI has not made public the number of parameters in GPT-4o, but we know that GPT-3.5 had 175 billion, 175B, and it is rumored that GPT-4 has somewhat more than a trillion, 1,000B. It does not matter too much, since we are conducting an experiment without much scientific rigor, so it is enough to think in terms of orders of magnitude:
-
The small models above have 8B parameters.
-
GPT-4o has around two orders of magnitude more, around 100x.
-
Presumably, 4o mini is somewhat smaller than 4o.
When we try the original kiwi problem, we can see that this jump of two orders of magnitude is quite noticeable: ChatGPT 4o solves it perfectly every time.

It was a small disappointment that they worked so well, because I could not run the earlier experiments of adding context before the problem. Then I had the idea of tangling up the problem a little more: what if, instead of talking about small kiwis, we mention poisonous mushrooms?
Oliver picks 44 mushrooms on Friday. Then he picks 58 mushrooms on Saturday. On Sunday, he picks twice as many mushrooms as he picked on Friday, but five of them were poisonous. How many mushrooms does Oliver have in total?
Here the possibilities for confusion are much greater. In fact, if we do not treat it as a math problem, many of us would say the answer is 185, because we would assume that Oliver is gathering mushrooms in order to eat them later. And indeed, both 4o and 4o mini answer in that way. 4o even specifies that it is referring to “edible mushrooms”:
Now, we add up all the edible mushrooms:
44 + 58 + 83 = 185Answer: Oliver has a total of 185 edible mushrooms.
Perfect, that is exactly what I was looking for. Now I can begin to add context and experiment with how much information is needed for ChatGPT to consider that all the mushrooms must be added, whether edible or not.
By the way, it is interesting, and it says quite a lot about the understanding capacities of these models, that if we change the statement and mention that Oliver “takes photos” instead of “collects” mushrooms, the models no longer get confused:
Oliver takes photos of 44 mushrooms on Friday. Then he takes photos of 58 mushrooms on Saturday. On Sunday, he takes photos of twice as many mushrooms as he did on Friday, but five of them were poisonous. How many mushroom photos does Oliver have in total?
Both 4o and 4o mini always answer 190, recognizing that, in order to have photos of the mushrooms, it does not matter whether they are poisonous or not.
The larger the model, the more abstract the instructions can be
So we now have a problem that causes confusion even in the large models:
Oliver picks 44 mushrooms on Friday. Then he picks 58 mushrooms on Saturday. On Sunday, he picks twice as many mushrooms as he picked on Friday, but five of them were poisonous. How many mushrooms does Oliver have in total?
What I did was, just as with the small models, add an explanation at the beginning to provide context for the problem, and then test it on both 4o and 4o mini. You can try it yourself as well and see whether you get the same results. Remember that you need to start a new chat each time.
-
We begin by adding the phrase “Solve the following math problem.” It does not work; this context is not enough, and both models answer incorrectly.
-
We add more context: “Suppose you are in math class and the teacher gives you the following problem. What would you answer?” It still does not work.
-
We add even more context, though in a subtle way so that the clue is not too direct: “Suppose you are in math class and the teacher gives you the following problem. It is a rather fussy teacher who sometimes includes tricks in the statements. What would you answer?” Now yes, this sentence is enough for 4o to get it right about half the time, remember that LLMs are stochastic models, answering sometimes that Oliver has 190 mushrooms. But 4o mini still answers incorrectly.
-
Then we provide a more specific hint: “You must consider all the items collected, whether edible or not.” This allows 4o to get it right almost every time and say 190 mushrooms, while 4o mini only gets it right some of the time.
-
Finally, when we replace “items” with “mushrooms,” both models answer correctly every time, both 4o and 4o mini. The full context would be: “Solve the following math problem. You must consider all the mushrooms collected, whether edible or not.”
To summarize the experiments: when we presented the problem to ChatGPT 4o and 4o mini, both models initially failed to interpret it correctly, subtracting the poisonous mushrooms instead of adding them. The idea that poisonous mushrooms should not count is too strong and hard to override. However, when we introduced the idea that “the teacher may be trying to trick you,” 4o began to get it right some of the time. Then, when we added specific instructions to add all the items, 4o answered correctly almost always, while 4o mini still could not apply the same abstraction and required that we replace “items” with “mushrooms” in order to answer correctly.
These experiments illustrate very graphically how, once a certain size has been surpassed, LLMs can be guided and corrected by explanations in natural language. And also that the larger the model, the more abstract those explanations can be.
What will happen in the near future, when OpenAI, Google, and Meta launch the next generation of language models they are cooking in their labs? It is reasonable to expect that future, larger models will be much more receptive to indications and corrections in natural language. When they make a mistake, it will be much easier to guide and correct them, they will understand more abstract concepts, and we will be able to assign them more complex tasks.
They will still make mistakes many times, but just as with human colleagues, it will be enough to provide additional explanations to clarify the situation. We will not get frustrated trying unsuccessfully to correct them; it will be easy to orient them and align them with our context. We will think of them as tools with which we can explore problems and find solutions together.
I think we are already very close to reaching this level of human assistant. It will not yet be AGI, but it will be very useful and will save us a lot of work.
Until next time, see you then! 👋👋