April 1 to 15 (#7 of 2024)
👋👋 Hi, I'm Domingo!
We have already made it through the first third of the year and are fully entering 2024. We no longer hesitate when writing 2024. And this is already the 7th installment of this newsletter, which began as a happy New Year's idea ("let's see how it goes") and that I enjoy writing more and more each time.
There are less than 3 months left until Apple's developer conference, WWDC24, where it seems Apple is going to present some new developments around generative AI applications in its products. How much truth is there to that?
Let us get started. Thank you very much for reading me!
🗞 News
1️⃣ How hot is this summer going to be? I recently discovered the website https://climatereanalyzer.org, run by the Climate Change Institute at the University of Maine. They gather data every day from multiple sources and display it in a very convenient graphical format.
Two especially noteworthy pages on the site, which I have already added to my bookmarks so I can visit them every month, are the one for the evolution of surface temperature and the one for the evolution of sea temperature. You can select the part of the world you want to consult and get data, for example, for the Northern Hemisphere or the North Atlantic.
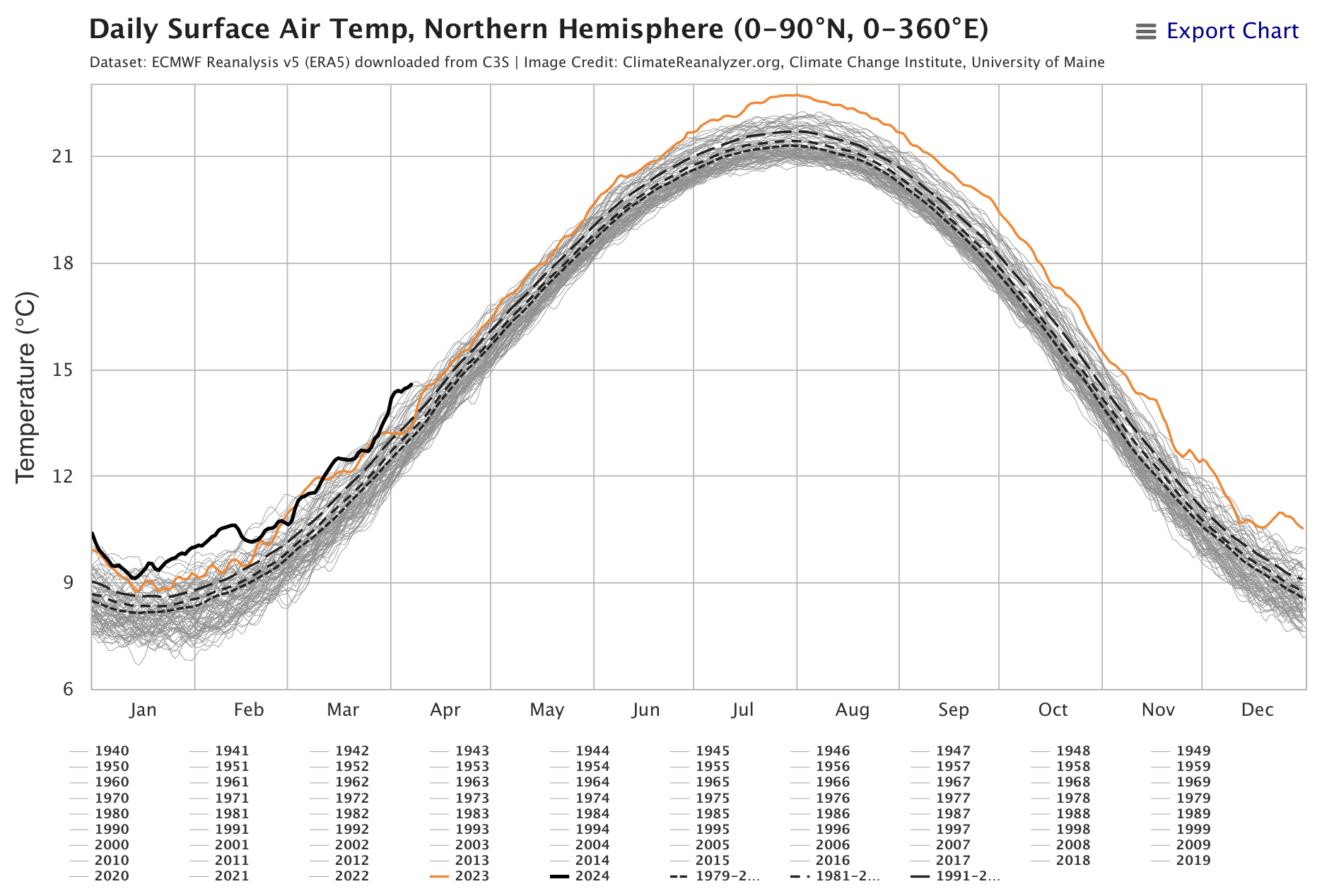
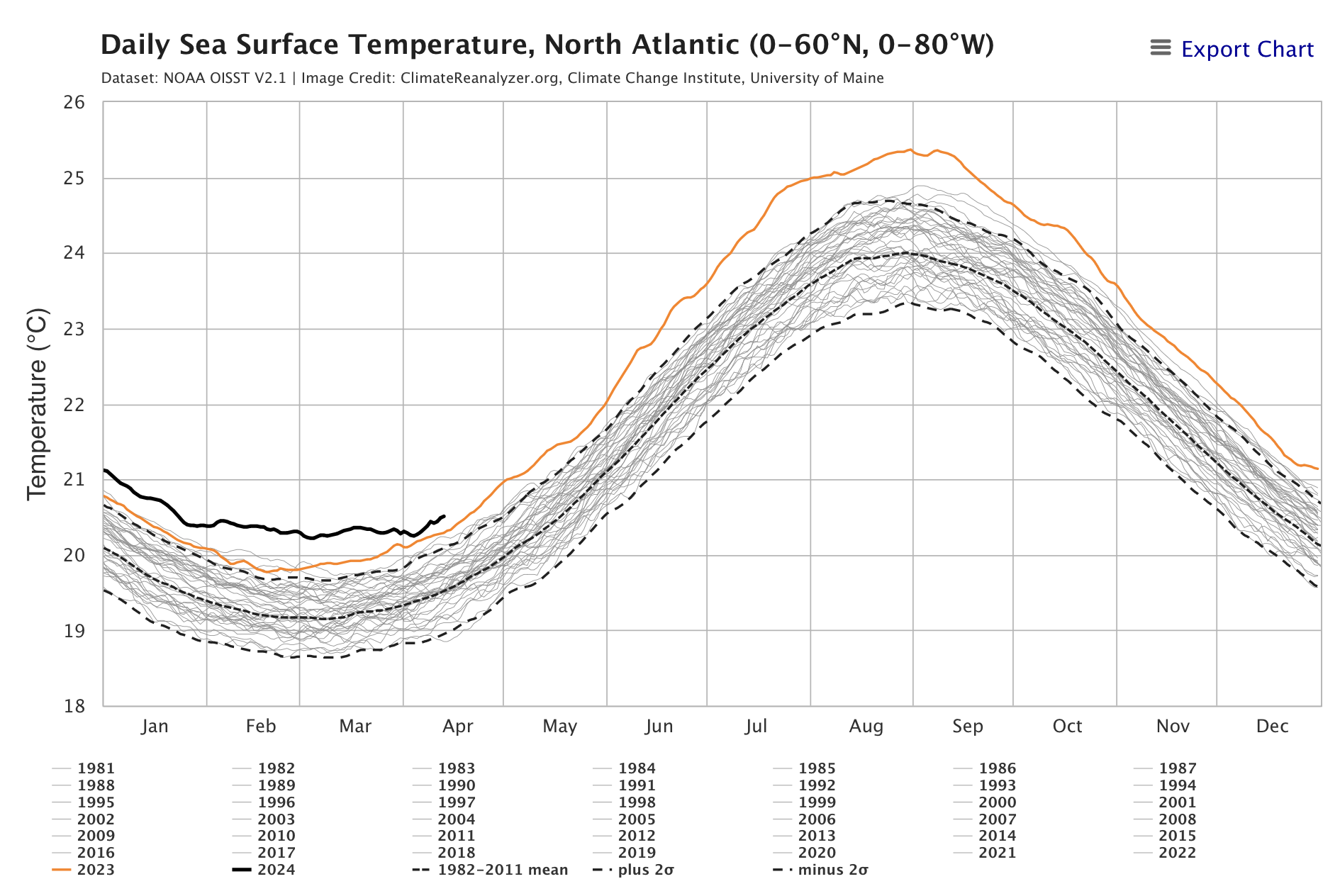
The figures show the latest data as of yesterday. Last year's record, in orange, is off the charts. That reflects what we all felt last summer: that it was the hottest one in recorded history. And the current year's record, in black, is above it, although the slope seems a little less steep and, if we are optimistic, it may not rise as much as last year did. We will have to keep checking the site to confirm it.
Why have temperatures risen so much since last year? It is not entirely clear. The temperature evolution models used to predict climate change are long-term models, and they do not help explain sharp fluctuations in a single year. One reason some scientists have proposed is the massive eruption of the underwater Hunga Tonga volcano, located in the South Pacific, in January 2022.

Eruption of the underwater Hunga Tonga volcano seen from space.
It was an extraordinary eruption that sent 146 million tons of water vapor into the Earth's stratosphere, around 10% of the water vapor already present in that layer of the atmosphere. Unlike earlier eruptions such as Krakatoa or Pinatubo, which injected gases and ash into the atmosphere that had a temporary cooling effect on the Earth's surface, water vapor has a greenhouse effect that increases temperature and causes chemical changes that may reduce ozone.
This greenhouse effect has not been studied very extensively, and there is no scientific consensus on its real impact, but it may be partly responsible for the extraordinary increase in temperature over the last few years. The effect will disappear once the extra water vapor is finally removed from the atmosphere. Although there are no clear estimates of how long that will take, experts speak of a few years. Let us hope not too many.
2️⃣ Some people are already saying Vision Pro has been a failure. Others are wondering whether they regret buying it.

YouTube video by AlenhandoroVR.
It is still far too early to pin labels on the launch. But we can start reflecting on the product and its possible evolution. I am interested in the evolution of Vision Pro for several reasons.
First, from a technological point of view, it is one of the computing devices that integrates the largest number of state-of-the-art components. Watching how the headset evolves will be almost equivalent to watching the evolution of the most advanced computing technologies: processors, displays, cameras, LiDAR sensors, and so on. On top of that, from a product design perspective, it will be very interesting to see the direction future models take over the next few years. Will Apple increase the headset's resolution at the expense of keeping its weight high? Will there be a lighter model? Will the external display showing the wearer's eyes change?
The second reason is software. What new styles of interaction are going to be created? To what extent will the device expand our capabilities? What will we be able to do with this new computational tool? I have always been interested in viewing computing through Steve Jobs's metaphor of the bicycle for the mind 1, and I think Vision Pro could be a spectacular step in that direction.
And the third reason is entertainment.
My wife and I go to the cinema almost every week. We go out for a while, watch a film, have dinner. That cannot be replaced by watching a movie with the headset, no matter how spectacular the Avengers Tower environment, the spatial audio, or the 3D effects may be. But that does not mean people will never watch films through the visor. For example, doing so while traveling by plane or train will probably become increasingly normal. Video did not kill the radio star; The Buggles got that one wrong. On the contrary: now we watch YouTube and listen to podcasts.
I am also curious about immersive experiences. Will many more of them be produced? Will we be able to watch plays, musicals, or concerts? We are not football fans, but we do sometimes watch Nadal or Alcaraz. Or the national team's basketball games. Ten years from now, will it be possible to watch them live as immersive experiences?
A spectacular feature Apple has introduced this fortnight in the new VisionOS 1.1 beta is spatial personas. Now the people you call on FaceTime no longer appear in a window. Instead, they appear next to you, in your space, in three dimensions. You can see their face and hands. You can move closer, crouch down, make gestures together, and even high-five each other.

This is what the new FaceTime video calls on Vision Pro look like. Frame from a video posted on X.
And in addition, almost as important as the above, everyone in the conversation can share and interact with apps using SharePlay . For example, they can write on a shared whiteboard or inspect 3D figures placed on it, or watch a movie or series together at the same time.

On the downside, Apple has released a short immersive film with a compilation of soccer highlights from the American league. The film has problems, because the editing is designed like a normal film, with cuts that are too fast for an immersive experience.
The future will tell us how the headset evolves. I do not share Marco Arment's opinion, from ATP, that it can already be considered a failure. It is still far too early to make such a categorical judgment, only three months have passed since it went on sale. I agree more with Siracusa, Mike Hurley and Casey Liss, or Jason Snell, who see it for now as an evolving experiment.
Apple has just given its promotion another push, publishing a press release about its use in business and putting it back on the home page, highlighting experiences such as using it while traveling by plane.
That is how products succeed: by finding success cases and then building from there. We will see how it evolves. As Siracusa says in the podcast linked above, we need to wait at least three years before calling it a success or a failure. I propose that we bet on three possible scenarios:
-
A hugely successful product, for which Apple presents multiple versions with different configurations and capabilities, similar to what the MacBook is today.
-
A product with limited but real success, a niche product. Well regarded and well supported by Apple, with frequent software and content updates, and with hardware updates spaced farther apart, similar to the Apple Watch Ultra today.
-
A product that Apple leaves without updates for a long time, with few diversification bets, little investment in software and content, and less and less success, similar to what is happening with the Mac Pro.
For now, I am moderately optimistic and I am betting on scenario 2. I will revisit this prediction in a year.
3️⃣ Still with Apple, there is a lot of buzz that at the upcoming WWDC24 they are going to launch major developments in generative AI. There are rumors of talks with Google and OpenAI, or of Apple developing its own models.
Some people are even saying that Apple is already launching LLMs, as the following tweet suggests.
How much truth is there to all this? I would like to comment on it, to explain how to tell rumors from actual news.
In hardware, we are already used to rumor cycles: Chinese supply chains leak some story based on prototype units or components, Mark Gurman more or less confirms it, a few moderately serious sites such as MacRumors, 9to5Mac, Applesfera, or Xataka pick up the rumors and identify them as such, and then everything gets out of hand in clickbait articles from outlets that sell the rumor as already confirmed news.
Something similar is happening with generative AI. But now the origin of the rumors is different: scientific publications.
Apple has a fairly powerful research department: Apple Machine Learning Research.

If we go to that site, we can see all the scientific publications, papers, that Apple researchers are presenting at journals and conferences. Some papers even have a GitHub repository. For example, this one from February 2024, Scalable Pre-training of Large Autoregressive Image Model, which presents various vision models applicable to LLMs, has this repository.
In addition, before being accepted at conferences, papers are also uploaded to the scientific repository arXiv, something common in fields such as computing and physics. That is the case for the papers related to the Ferret language model:
-
(April 2024) Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
-
(April 2024) Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
-
(October 2023) Ferret: Refer and Ground Anything Anywhere at Any Granularity - GitHub repository.
One of the lead authors of these papers is the young researcher Haotian Zhang, a brilliant computer scientist who defended his PhD only 2 years ago at the University of Washington and has been working at Apple ever since.
So has Apple launched any LLM? No. Apple is starting to research the topic. On top of that, Apple is, for now, following a fairly transparent philosophy regarding its research department, publishing all results openly. But let us remember that they are only that: scientific papers. They are not production models, not even pre-production models. The difference between a scientific paper and a product is similar to the difference between a patent and a final product. A final product is the result of dozens of patents and papers.
OpenAI was founded in 2016. In 2018 they published a paper called Improving Language Understanding by Generative Pre-Training, which was the origin of GPT. In 2019 they presented GPT-2, in 2020 GPT-3, and in December 2022, ChatGPT.
Apple is now, in 2024, at a point similar to where OpenAI was in 2018 or 2019. They may be able to launch a model in a couple of years. But not now.
4️⃣ It has now been 10 years since Monument Valley, the groundbreaking game from the British company ustwo games that captivated many of us with its gameplay, graphics, and interactions.

Different screens from Monument Valley.
The company has published a remembrance on X and a commemorative video on its website. A few very interesting articles about its history have also been published, at gamesindustry.biz and wallpaper.com, and I love the sketches of some of the game's mechanics and puzzles.

Sketches from Monument Valley.

More sketches. Can you buy a PDF of that notebook? I want it ☝️.
If you have not played it yet, it is available on multiple platforms. If you played it 10 years ago, like I did, you probably do not remember the solutions and can enjoy it all over again. Run, you fools!
5️⃣ We finish with a curious story about a problem that is hard for LLMs to solve, the so-called A::B problem.
On April 6, Victor Taelin, a Brazilian programmer and entrepreneur, posted a challenge on X that got more than 1 million views: he would give USD 10,000 to anyone who found a prompt that could get some model to solve a logic problem that he believed current models were incapable of solving.
Victor Taelin's X profile. He has lost USD 10,000 on a bet about LLMs.
Let us quickly look at the problem, it is not very complicated. Taelin posed it in this X post from April 5 and explains it in more detail in this Gist. It consists of processing a string formed by the symbols A#, #A, B#, and #B. For example, the string:
B# A# #B #A B#
You have to check the symbols from left to right, two at a time. By default, nothing is done and the symbols are left as they are. But if the symbols have their # signs facing each other, looking at one another, then the following transformation rules must be applied:
Rule 1: A# #A => both symbols are removed\nRule 2: B# #B => both symbols are removed\nRule 3: A# #B => they become #B A#\nRule 4: B# #A => they become #A B#
Once the transformation has been applied, you move on and keep processing the rest of the string, leaving the transformed symbols behind. When you reach the end of the string, you start again from the beginning. The process ends when the resulting string no longer changes.
For example, the result of processing the original string would be the following. I put in brackets the pair of symbols being processed at each step:
Pass 1\n======\n[B# A#] #B #A B# => B# and A# do not have the # signs facing each other, so they stay the same\nB# [A# #B] #A B# => (Rule 3, they are transformed) => B# #B A# #A B#\nB# #B A# [#A B#] => They stay the same\nB# #B A# #A B#\n\nPass 2\n======\n[B# #B] A# #A B# => (Rule 2, both are removed) => A# #A B#\n[A# #A] B# => (Rule 1, both are removed) => B#\nB#
So the final result of processing the string
B# A# #B #A B#
is the string
B#
A lot of people attempted the challenge. The goal was to find a prompt that would allow an LLM to process strings of 12 symbols with a 90% success rate. In just a few days, someone managed it using Claude Opus, with an extremely complicated prompt of 700 lines, containing many explanations and many examples. A little later, someone else provided another, shorter solution of 400 lines, with which they won USD 2,500.
In the end Taelin had to admit defeat. And interestingly, the winning LLM was not GPT-4, but Claude. Good for Anthropic.
Still, I am not convinced. Any of us who has read the problem has understood it with far fewer than 400 lines and a single example. I suppose each new generation of LLMs will gain in abstraction ability and will be able to solve the problem with a smaller prompt. We will have to try it with GPT-5.
The problem with repeating the challenge on later models, GPT-6 and beyond, is that new LLMs will also be trained by reading all these posts, messages, and files, and they will know how to solve the problem out of the box. But GPT-5 must already be in the oven, so we should still be able to do the experiment with it. It has not had time to read all this in training.
👷♂️ My fifteen days
👨💻 Tinkering
A Moodle working group has been created at my university, the University of Alicante, to share initiatives related to generative AI and language models. I am part of the group, and I uploaded a 20-minute video in which I comment on the experiment that I already presented here about configuring an LLM to act as a tutor that advises students on changes to their programs so that they comply with certain guidelines that we emphasize in our course, namely good practices in Functional Programming.
For now, the Moodle working group is restricted to the University of Alicante, so I have also uploaded the video to YouTube so anyone can watch it and comment on it.
There is not much in it that differs from what I already told here, but it may be interesting to watch the example of the tutor in action. And at the end of the video I make a fairly obvious proposal: we really need some kind of institutional service of our own that would allow teachers and students to experiment with LLMs. To configure them, give them guidelines, and deploy them so they can be tested. We will discuss it within the working group itself and see whether we reach any conclusions.
📖 A book
I have kept reading Liu Cixin's trilogy. Specifically, its second part, The Dark Forest . It is a much better book than the first one. Deeper, with more ideas, more characters, and significantly better written. It was published in 2008, two years after the first book, and you can feel Liu's development and greater maturity, or perhaps the fact that, after the first book's success, he was finally able to devote to it the time it needed.

The first season of the Netflix series adapts up to the middle of this second book. Once I reach the point where the series ends, I will stop reading and pick it up again a couple of months before the second season is released, which, by the way, Netflix still has not announced.
📺 A series
We are liking the Apple TV+ British series Criminal Record very much, we are halfway through it. It is a police series set in the suburbs of London, in which Cush Jumbo has to face what looks like a case of police corruption involving Peter Capaldi.

Two excellent actors whom we have already seen recently in other productions. Capaldi in the excellent and little-known The Devil's Hour on Prime. And Jumbo as a lawyer in The Good Fight .
And we finish with a list of the films we watched this fortnight to which I gave four stars or more on Letterboxd:
-
The Host (2006)
-
28 Weeks Later (2007)
-
Anatomy of a Fall (2023)
-
Scoop (2024)
-
The First Omen (2024)
Until the next fortnight, see you then! 👋👋
The interview is from the early 1990s, before the Internet, and it is excellent because of the explanations Jobs gives to justify the importance of computers. At that time these kinds of arguments were necessary to convince future buyers. Just like now with Vision Pro. I also found an even older Jobs presentation, one of the first times he used the metaphor. The presentation is from 1980, and many of the ideas that made Apple revolutionize computing are already there: presenting the computer as a tool for everyone, not just the business world, and making its use personal, easy, and intuitive.