April 16 to May 15 (#8 of 2024)
👋👋 Hi, I'm Domingo!
After a fortnight's delay and with my issues around organization, time management, and procrastination more or less under control, here I am with a new issue. This time we are reviewing not one but two fortnights.
A small announcement: from now on, I intend to publish on Fridays, after either the first or the second fortnight of each month. Most of the newsletters I read come out on a fixed day of the week, and it seems like a good idea to try that. That way, you will know that every other Friday I will show up in your inbox. And on some Fridays when it is not due, there will be a surprise. You will see next week.
A lot of news in a month. Above all, a lot of new models. Let us get to it, and thank you very much for reading me.
🗞 News
1️⃣ On April 18, Meta released its new versions of Llama, the Meta Llama 3 models [Build the future of AI with Meta Llama 3 - meta.com and Introducing Meta Llama 3: The most capable openly available LLM to date - meta.com].
Let us remember that Llama models are open LLMs, available to download, fine-tune, and use in any application. That said, if we use these models or create new models based on them, we will need to include the phrase “Built with Meta Llama 3” or include the name “Llama 3” at the beginning of the model name [META LLAMA 3 COMMUNITY LICENSE AGREEMENT - meta.com].
Specifically, Meta has published two models, one with 8 billion parameters and another with 70 billion parameters: Llama 3 8B and Llama 3 70B. According to the benchmarks published by Meta itself, these models are the best when compared with others of similar size.
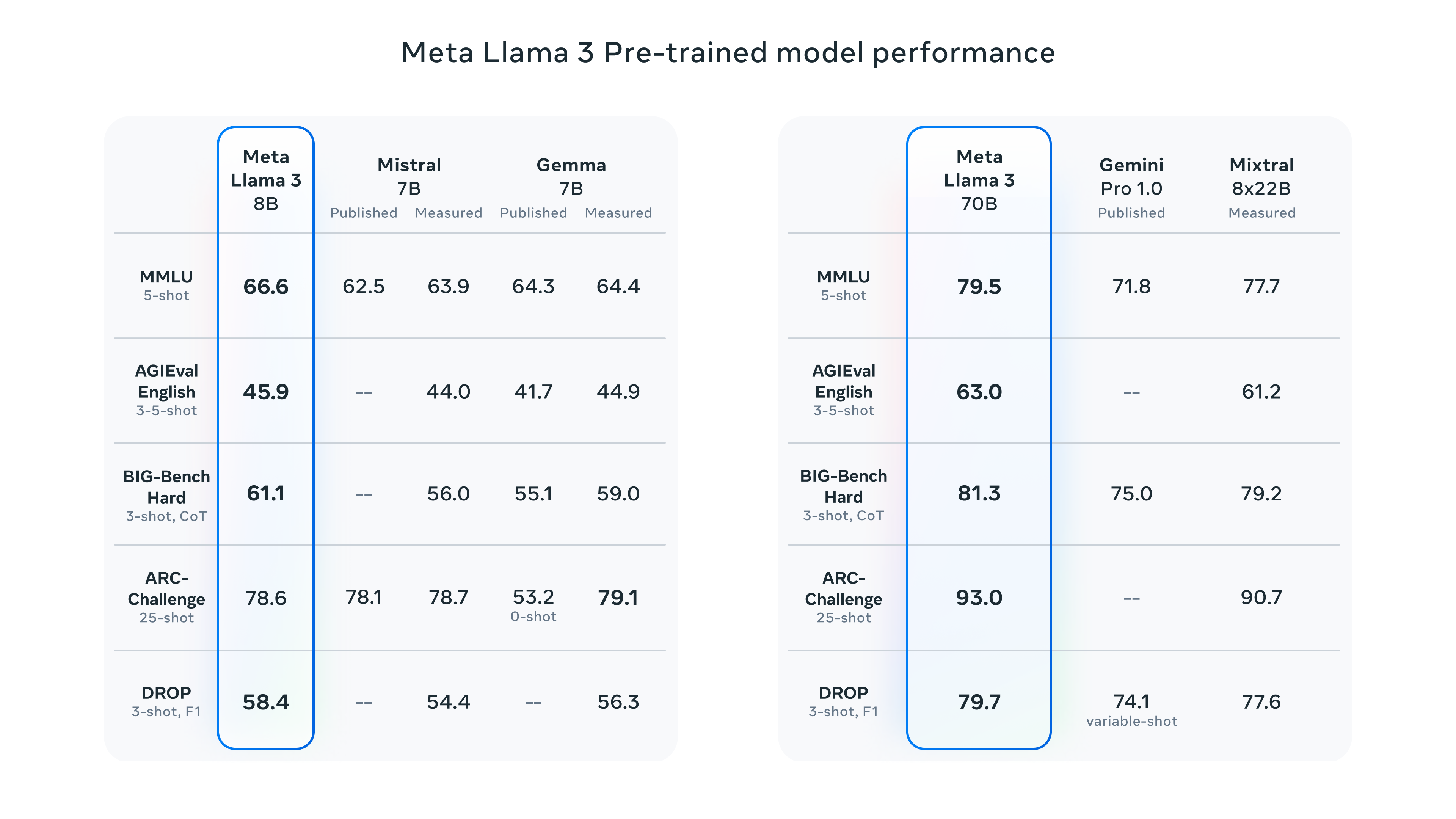
They are still training the larger model, with more than 400 billion parameters, called Meta Llama 3 400B+. However, they have already shared preliminary results that place it ahead of GPT-4 and on a par with Claude 3 Opus.
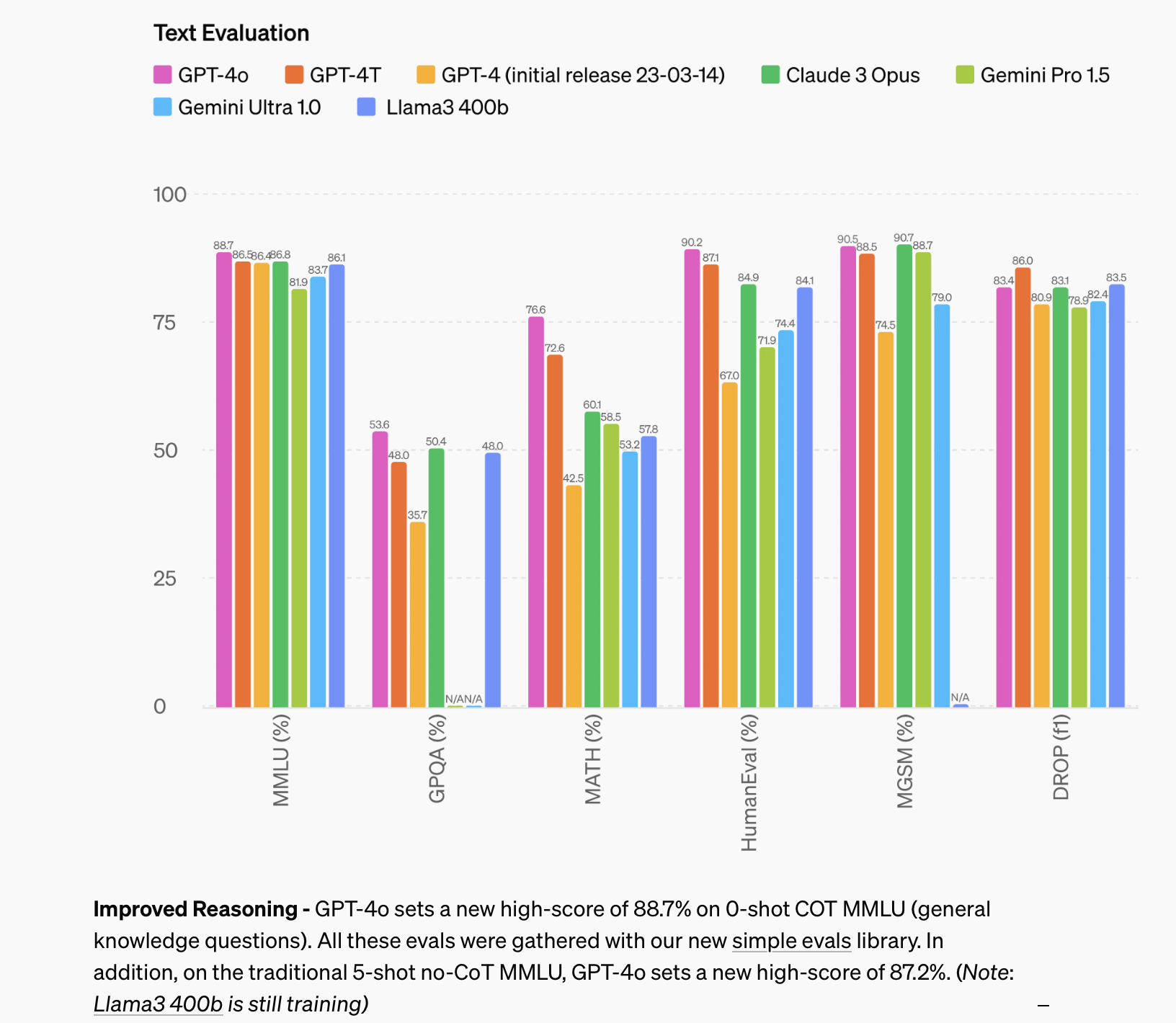
Performance of the latest LLMs on the most important benchmarks [Hello GPT-4o - openai.com]
It is very interesting that these models have been built using very careful processes, for example by using high-quality datasets and texts, which have allowed them to achieve better results than much larger previous models. For example, the smaller model, Llama 3 8B, gets clearly better scores than the 70B model from a year ago, Llama 2 70B. Similarly, Llama 3 70B scores higher than GPT-3.5, with its 175 billion parameters.
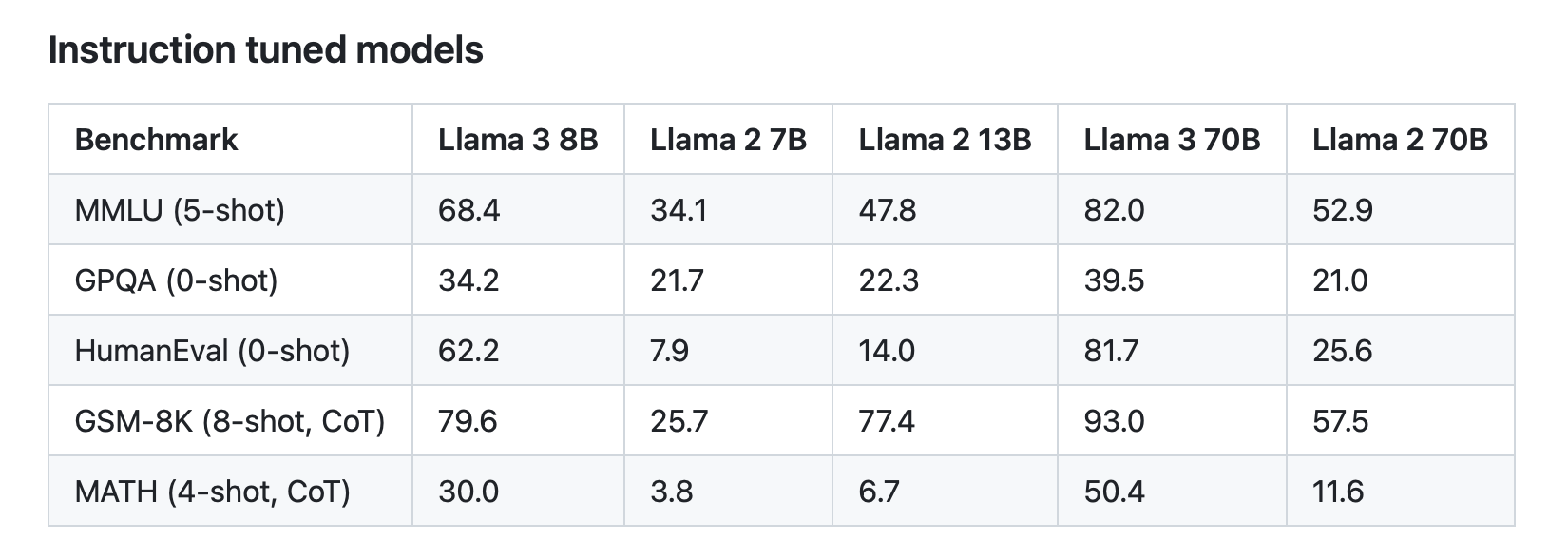
Scores on the main benchmarks for Meta's models [Llama 3 Model Card - github.com].
The size of a model matters not only for performance, but also because it determines how much space it takes up. The Llama 3 8B model is a little over 13 GB in size. In its quantized version, which reduces parameter precision to save space, it takes up roughly 4.21 GB. That size would make it possible to run it on a high-end mobile device. Although there are advanced techniques that make it possible to use models from SSD storage memory [Apple Develops Breakthrough Method for Running LLMs on iPhones - macrumors.com], the most common approach is still that all the model weights need to be loaded into device memory in order to run it. For example, my iPhone 12 has 4 GB of RAM and could not run it. The latest models, the iPhone 15 family, have 6 GB in their basic configurations, iPhone 15 and 15 Plus, and 8 GB in their advanced configurations, 15 Pro and 15 Pro Max. The basic models would be cutting it very close, while the Pro models could run it. The ability to use a local LLM is surely going to become a differentiating factor in smartphones from now on.
If you want to play around with the models, you can find them on Hugging Face [Meta Llama - huggingface.co] and read the post published there as well [Welcome Llama 3 - Meta’s new open LLM - huggingface.co].
2️⃣ On April 23, Microsoft released its Phi-3 models [Introducing Phi-3: Redefining what’s possible with SLMs - microsoft.com and Microsoft’s Phi-3 shows the surprising power of small, locally run AI language models - arstechnica.com]. These are small models:
-
Phi-3-mini, with 3.8 billion parameters and a 4,000-token context window, although Microsoft also introduced a 128K-token version called “phi-3-mini-128K”.
-
Phi-3-small, with 7 billion parameters.
-
Phi-3-medium, with 14 billion parameters.
The models are described in detail in the article published on arXiv [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone], where Microsoft shows that the smallest model, quantized to 4 bits, can run on an iPhone 14 Pro. It is curious that Microsoft tests its language models on Apple devices.
The paper also presents an evaluation of these models, showing that they achieve results on benchmarks that are similar to, or in some cases even slightly better than, other small models, and are in some cases comparable to GPT-3.5.
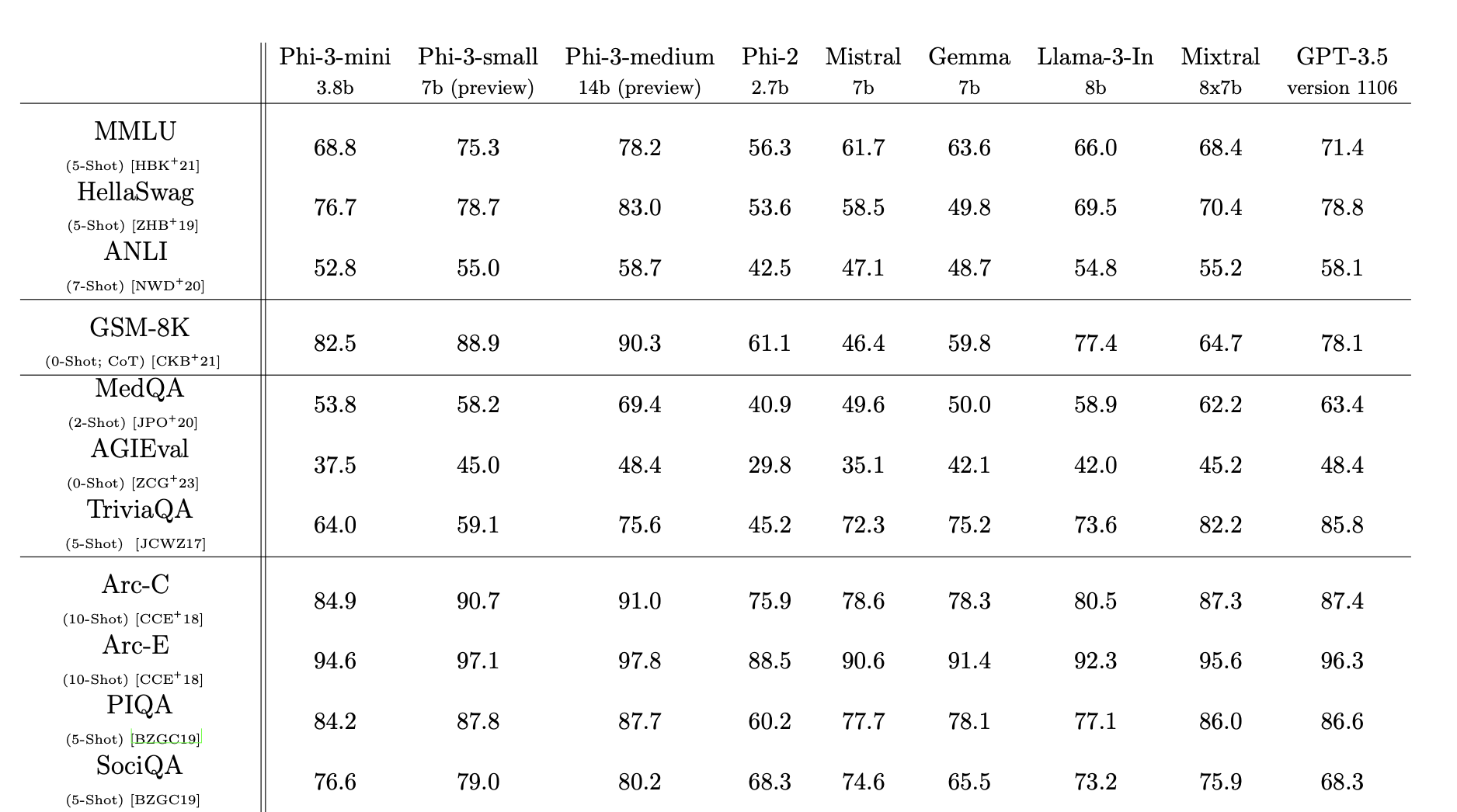
Results of Microsoft's small models on selected benchmarks, compared with other small models and GPT-3.5.
The models are also open and available on Hugging Face [Phi-3 family of models - huggingface.co].
An important competition is coming in the small-model space, where Apple is already taking its first steps, as the next item shows.
3️⃣ On April 22, Apple published several small models called OpenELM [Apple releases eight small AI language models aimed at on-device use - arstechnica.com and OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework - arxiv.org]. In the previous issue, we mentioned that Apple’s research department was publishing results from its first language models. Well, some of those models are already openly available on Hugging Face [OpenELM - huggingface.co] and can now be tested by the community.
These are still very basic models, with rather weak results compared with models of similar size. Even though Apple has really accelerated over the last year, it is still far behind research groups such as Meta and Microsoft, which in turn remain behind Google, Anthropic, and OpenAI.
I did a small investigation using the Wayback Machine into how the number of researchers in Apple's Hugging Face organization has evolved, with the result shown in the following chart:
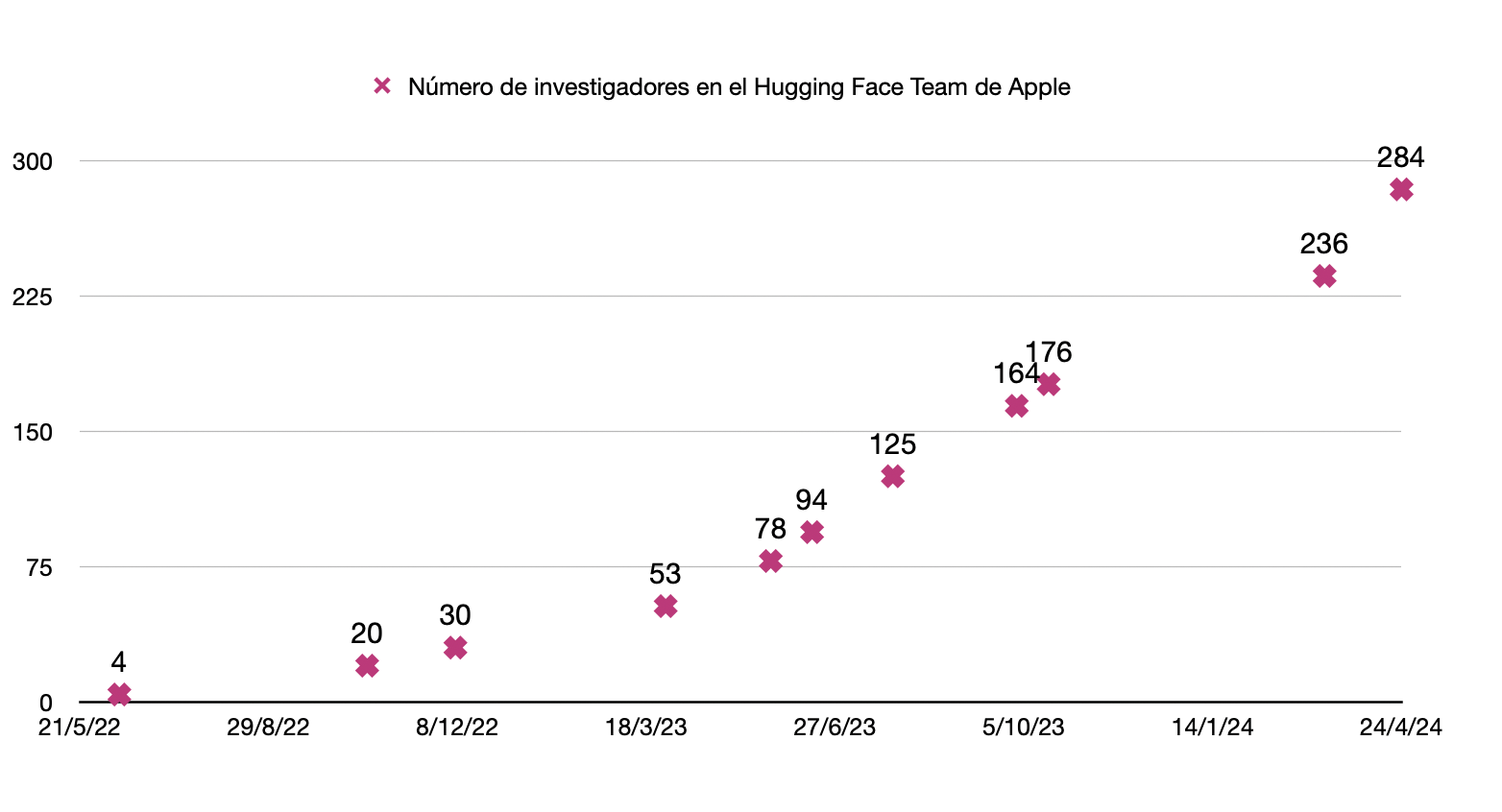
Evolution of the number of researchers in Apple's organization on Hugging Face [Wayback Machine - archive.org].
The number of Apple researchers on Hugging Face has gone from just 4 two years ago to 308 on the day I am writing this. I made the chart a week ago, when there were 284 researchers. In a single week, they added another 24.
The question now is what models Apple is going to use in its new iPhone 16 lineup, which will launch next September and this time really should arrive full of AI-related features. According to Mark Gurman, Apple's strategy is to use its own models for APIs, both on-device and in the cloud, while presenting an assistant, or chatbot, that will come from an agreement with OpenAI.

Mark Gurman's post on X about the language models Apple is going to announce at the upcoming WWDC.
We will know soon, at Apple's developer conference, which will take place in less than a month [WWDC24 - apple.com], where iOS 18 and all the AI features it will include will be presented.
4️⃣ And now we come to the high point of the month: on May 13, OpenAI held a special event where it presented its new model: GPT-4o [Introducing GPT-4o - youtube.com]. After the 4 comes the letter “o”, for “omni”, not the number zero.
This is a multimodal model from the ground up. It is a project that began more than a year ago, as its director, Prafulla Dhariwal, explained.
Post on X from the director of the GPT-4o project at OpenAI.
The fact that the model is multimodal means that it was trained from scratch using text, audio, and images. Although it works with video, it has not been trained on video sequences1. Instead, it breaks down the video it is seeing into still frames and analyzes each one. It can also produce the same kinds of elements it was trained on: text, audio, or video.
The version they have put into production is the one that outputs text. In the demo at the event, they showed how the model was able to generate audio. And they are still testing image generation, by the model itself rather than external models such as DALL-E, before releasing that in production.
At the OpenAI event, the model was shown functioning as an assistant. It is able to understand what we say, the tone in which we say it, and what we show it, and it can respond with voice. A super-natural voice that expresses emotions and congratulates and encourages us. Obviously, it was trained to resemble Scarlett Johansson in Her.
Just look at how impressive this is:
As Antonio Ortiz points out [Monos estocásticos 2x17 - cuonda.com], it is worth noticing the moment when the AI makes a mistake at the beginning and says it “sees the image” before the image has actually been shown to it. What becomes overwhelming comes afterward, when it apologizes and does so with a specific, completely human intonation that conveys a certain embarrassment about the mistake.
If we watch the video carefully, we can notice that the AI produces very different intonations throughout the conversation. It is incredible that all of this is the result of a model trained only to generate the next most likely token. We have already seen that this works with text. Now OpenAI has shown that the same idea also works when the next token can be a piece of a word, or a fragment of an image or of audio. The later fine-tuning phase is also very important, in which the model's output is adapted to the preferences we want, in what is called RLHF, Reinforcement Learning with Human Feedback.
Let me stress one very important thing, because there has been a lot of confusion about it. In the current ChatGPT application it is already possible to have a spoken conversation. But that is absolutely not the same thing as what GPT-4o does. What we currently have on our devices is really three different models glued together by an app: one model recognizes speech and transcribes it into text, another model, GPT-4, takes text as input and returns text, and another model transforms that response text into speech. GPT-4o is totally different. There is only a single model, a single neural network, that receives tokens in any of the modalities and outputs other tokens in response, which can be text, audio, or even an image. The neural network itself, the model itself, is what produces the intonation, and also understands it. There is no post-processing layer or specific algorithm that converts text into audio. It is astonishing.
Another of the most important characteristics of the new assistant is its extremely low latency, it responds almost instantly, and the fact that it can be interrupted at any moment simply by talking to it. The AI is continuously listening to us and stops speaking at that moment in order to hear us and answer again.
As for text-generation performance, the resulting model is better than the latest version of GPT-4 and has gone straight to first place on all the major benchmarks and rankings. It is not the leap people were expecting from GPT-5, but there is still a lot of year left, and OpenAI will surely give us more surprises.
5️⃣ The day after the OpenAI event, on May 14, Google held Google I/O, its developer-focused event. It was obvious that OpenAI had scheduled its event as counter-programming against Google. And with a lot of success, given the impact of all the references to Her and the freshness of the OpenAI event, compared with a Google event that felt heavier, longer, and less focused.
In its keynote, Google presented many projects in progress [Google strikes back at OpenAI with “Project Astra” AI agent prototype - arstechnica.com and Gemini breaks new ground with a faster model, longer context, AI agents and more - blog.google], but few finished products. Among the most interesting things were Veo, a video generator in the style of Sora, a new version of the image-generation model Imagen 3, and Project Astra, a voice-controlled assistant very similar to OpenAI's.
Google's assistant is also multimodal and can see the environment through the phone. They have not released it as a product yet, but they showed a recorded video, not a live demo like OpenAI did, showing how it works.
Although what we see is quite spectacular, especially with the final “where did I leave my glasses?”, the interaction and the assistant's voice are not as polished as OpenAI's.
Google did not reveal many characteristics of the language model underlying this new AI. The only thing they said is that it is multimodal, like GPT-4o, but they did not provide many details and it has not yet been possible to try it.
They also presented a small update to the already existing Gemini 1.5 Pro model, which will support contexts of up to 2 million tokens, including text, images, and video. That is wild. Now that it is finally available in Europe, it is time to try it and see what it can do. It is true that it does not get as much attention as other models, Claude for instance gets talked about much more, but in the rankings it sits very high and it is one of the most advanced models around.
Even though they did not present too many real products, Google I/O was full of references to AI. The video TechCrunch put together and posted on X is very funny:
6️⃣ Speaking of rankings and benchmarks, many of them have been updated lately. Let us go through them.
The first, one of the most widely used, is MMLU, which has just launched a new and more advanced version called MMLU-Pro [MMLU-Pro - huggingface.co]. It is a collection of 12,000 questions from different fields, biology, mathematics, economics, computer science, and so on. In the latest version they have increased the number of options for each question to 10. It is produced by the TIGER-Lab at the University of Waterloo.
The following figure shows the results of the latest model evaluation, with GPT-4o clearly in first place.
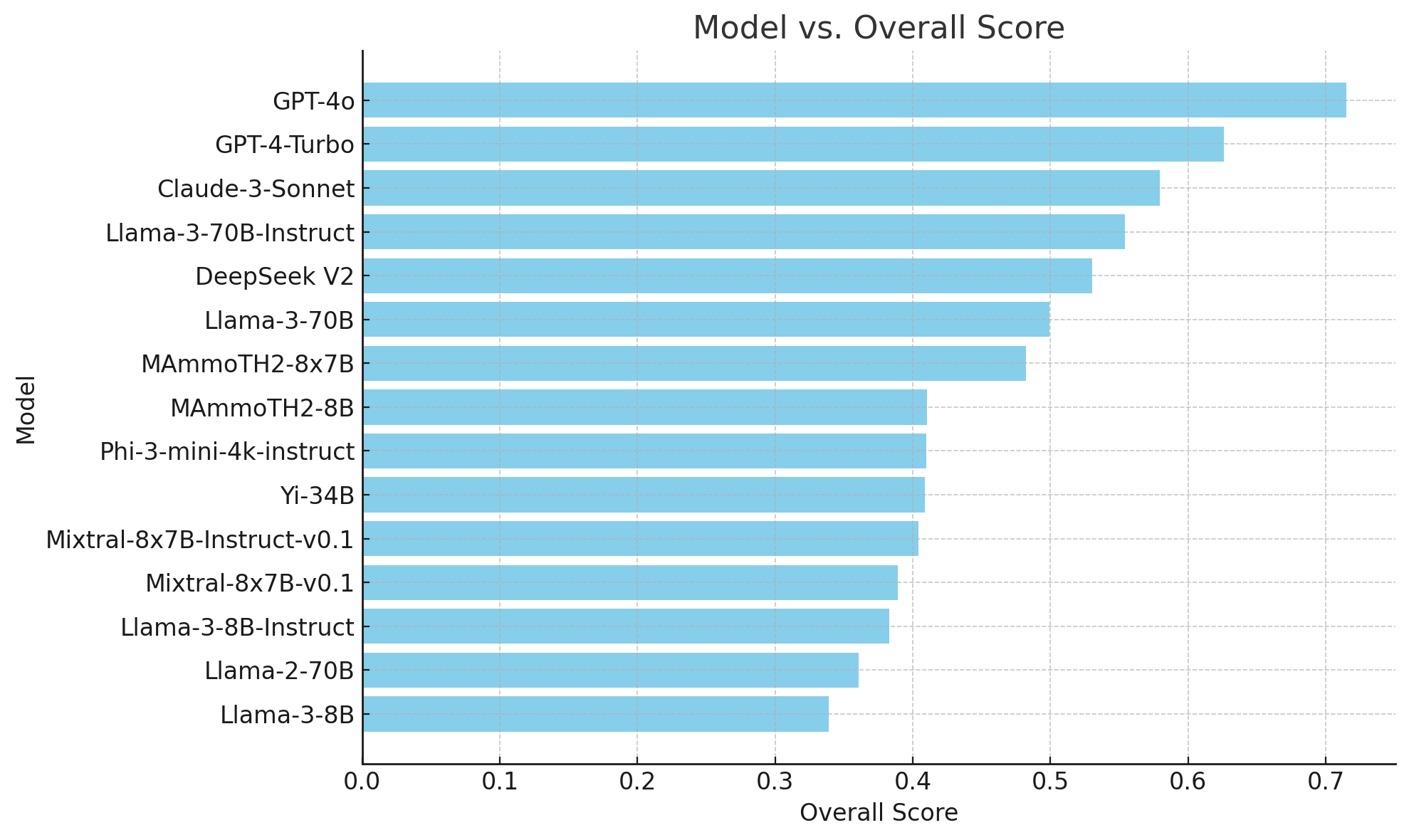
Wenhu Chen's post on X with the latest MMLU-Pro benchmark results.
Another type of ranking is the LMSys arena [LMSYS Chatbot Arena Leaderboard - lmsys.org], where the score is obtained from head-to-head matchups between pairs of models. Users give them prompts, read their answers, and then choose a winner. We can see that the clear winner is once again GPT-4o, under the codename it used for a few days, im-also-a-good-gpt2-chatbot, some distance ahead of another leading group formed by versions of GPT-4, Gemini-1.5-pro, and Claude-3-opus.
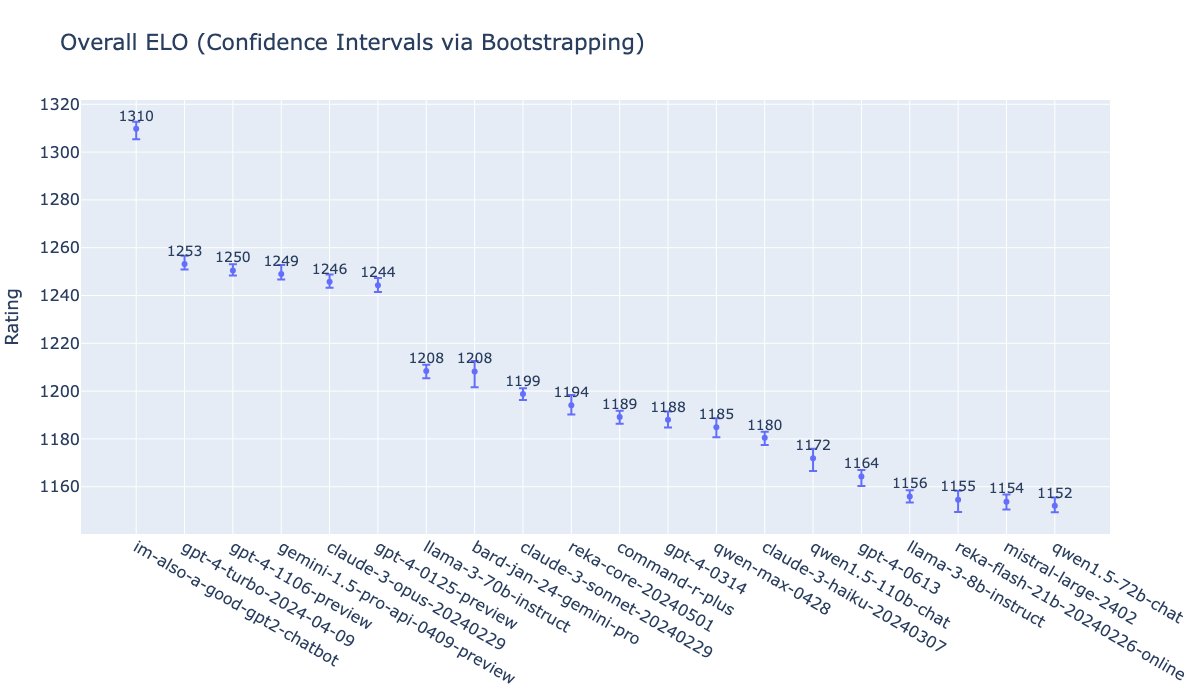
Another very interesting chart is the one Maxime Labonne publishes regularly on X, in which you can see how models evolve over time. On the vertical axis he places the score obtained in LMSys-Arena, and on the horizontal axis the date the model was released. He also marks closed models in red and open ones in green. This makes it possible to analyze how the different types of models progress.
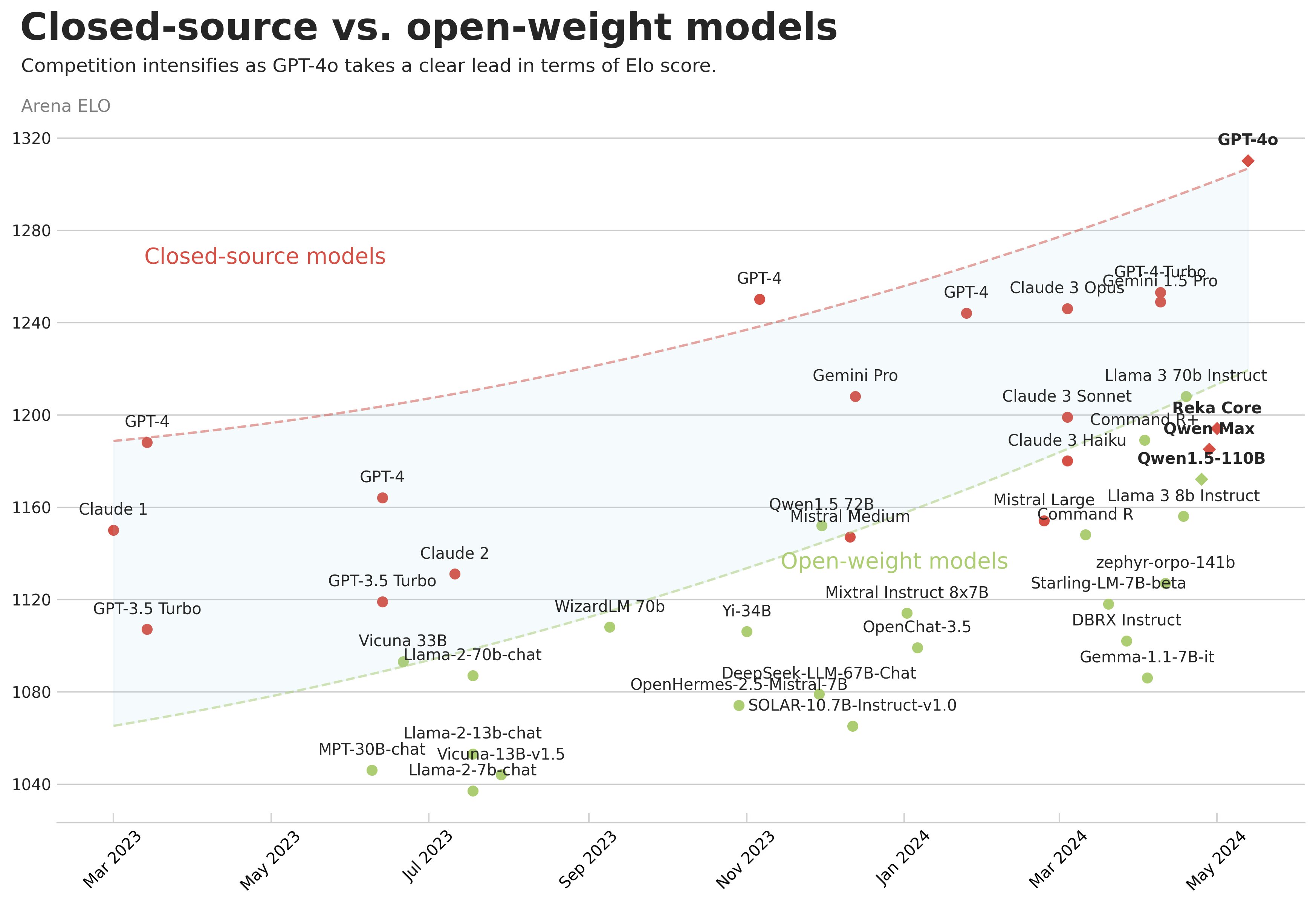
We can observe some very interesting things. For example, Meta's strongest current model, Llama-3 70B, is at the level of GPT-4 from a year ago. One year seems to be the time it takes for OpenAI's advances to diffuse into open models. I suppose the same will continue to happen in the future, and that by June 2025 we will see open models similar to the current GPT-4o. Another interesting thing to notice is that the upper curve keeps rising, which brings us to the next item.
7️⃣ The whole industry remains convinced that the scaling hypothesis [The scaling hipothesis - gwern.net] is true, and that larger models trained on larger and more varied datasets will obtain considerably better results. There are many ongoing investments, from Microsoft, OpenAI, Meta, and others, in building enormous data-processing centers, and even in building power plants to feed those centers.
For example, in the interesting interview with Dario Amodei [What if Dario Amodei Is Right About A.I. - apple.com] on the New York Times podcast The Ezra Klein Show, Anthropic's CEO shows himself to be fully convinced of this scaling hypothesis and talks about figures of 10 billion dollars to train future models:
"We are going to have to make bigger models that use more compute per iteration. We are going to have to run them for longer while feeding them more data. And that amount of chips multiplied by the time we run things on them essentially translates into a monetary value, because these chips are rented by the hour. That is the most common model for doing it. So current models cost on the order of 100 million dollars to train, give or take a factor of two or three. The models that are currently being trained, and that will come out at various points later this year or early next year, are closer to costing a billion dollars. So that is already happening. And then I think in 2025 and 2026, we get closer to five or ten billion.
So is it going to be 100 billion dollars? I mean, very quickly, the financial firepower you need to create one of these is going to exclude anyone except the biggest players."
Mark Zuckerberg, Meta's CEO, is somewhat more cautious in the interview on Dwarkesh Patel's podcast [Mark Zuckerberg - Llama 3, Open Sourcing $10b Models, & Caesar Augustus - dwarkeshpatel.com]:
"This is one of the big questions, right? [the exponential growth in model performance] I think nobody really knows. One of the hardest things to plan around is an exponential curve. How long will it keep going? I think it is probable enough that we will keep advancing that it is worth investing the 10 billion, or more than 100 billion dollars, into building the infrastructure and assuming that if it keeps going, you will get really amazing things that will make incredible products. I do not think anyone in the industry can tell you with certainty that it will continue scaling at this rate. In general, in history, you run into bottlenecks at certain points. Right now there is so much energy behind this that perhaps those bottlenecks will be overcome fairly quickly. I think that is an interesting question."
And regarding the size of future models and whether Meta will also release them openly:
"We have a roadmap of new releases that are going to bring multimodality, more multilingual capability, and larger context windows as well. Hopefully, at some point later this year, we will be able to release the 405 billion parameter model."
"Obviously we are very in favor of open source, but I have not committed to releasing absolutely everything we do. Basically I am strongly inclined to think that open source will be good for the community and also for us because we will benefit from the innovations. However, if at some point there is a qualitative change in what the thing is capable of doing, and we feel that it would not be responsible to make it open source, then we will not do it. It is very hard to predict."
👷♂️ My thirty days
Even though a whole month has passed since the previous issue, I do not have many updates to share. Not in books, I am still with The Dark Forest and have not progressed very much, and not in the things I have been tinkering with.
I am going to highlight the two films I liked most out of everything we watched.
📺 Two films
Two very different films, but I liked both of them a lot2.
The first is All of Us Strangers, by Andrew Haigh, with tremendous performances by Andrew Scott and Paul Mescal. A very personal and profound film, moving and thought-provoking. And with a soundtrack full of evocative songs for those of us who were young in the 1980s.

And the second is Kingdom of the Planet of the Apes, by Wes Ball. A return to adventure and to the themes I find most interesting in the saga: the formation of ape society, its relationship with humans, the inverted power relations between apes and humans, and the rewriting of history by the victors.
Some scenes reminded me of the original Charlton Heston film, and I had the feeling that the story is moving in that direction. I want more.

And that is it for this month. Until the next fortnight, see you then! 👋👋
At present there is no language model that has been trained on video sequences. There is currently no computing power available to carry out such training. Perhaps it will happen with GPT-6 or GPT-7, and that really would be revolutionary, because a model of that kind could learn and generalize how the real world works, the physics implicit in the motion of objects. And in turn, it could apply those concepts to the other modalities, for example by understanding spatial relations better when we talk about far/near or left/right.
My daughter Lucía is going to scold me for not including Challengers, but she already knows why 😂. I promise to comment on the film the next time I watch it ❤️.