La mejora de los LLMs en 2025: no hubo muro
Hace un año publiqué una lista de 7 preguntas para 2025 sobre LLMs. La idea era apartarme un poco del ciclo de anuncios de los laboratorios y de la inmediatez de las redes sociales y obligarme a evaluar el progreso con un criterio más estable y objetivo, alejado de sensaciones.
Me pareció también una buena forma de mostrar los aspectos que me parecían más relevantes en ese momento, los que podían dar alguna indicación sobre la posible evolución futura de estas tecnologías.
La primera de las siete preguntas era: ¿hemos llegado en 2025 a un “muro”? Es decir, ¿se ha frenado la mejora de los LLMs por falta de datos de aprendizaje? ¿se ha llegado al final de la curva logarítmica de mejora? ¿se ha frenado el escalado?
Para contestarla voy a fijarme en tres señales, sin complicarlo demasiado:
- tamaño / familias de modelos (qué modelos comerciales y abiertos publican los laboratorios)
- coste (si conseguir mejores resultados cuesta mucho más dinero), y
- resultados en benchmarks (resultados objetivos de mejora de los modelos).
Escribo esto a finales de enero de 2026, con la perspectiva y los datos de todo 2025. Mi conclusión adelantada: en 2025 no ha habido muro, pero sí un giro interesante en cómo están mejorando los modelos.
Qué predecían las leyes de escalado
Durante años, la historia “oficial” del progreso en LLMs era bastante simple: si aumentas escala (modelo + datos + cómputo), el rendimiento mejora de forma predecible. No en saltos, sino como una curva suave con rendimientos decrecientes: cada vez cuesta más conseguir la misma mejora.
Por ejemplo, los papers de Jared Kaplan et al. (2020), Scaling Laws for Neural Language Models (OpenAI) y de Hoffmann et al. (2022), Training Compute-Optimal Large Language Models (“Chinchilla”, DeepMind) habían establecido con claridad las leyes de escalado en el entrenamiento de LLMs, mostrando que para conseguir mejoras similares en los nuevos modelos hay que aumentar un orden de magnitud el tamaño de los mismos.
La idea importante es esta: si quieres mantener el ritmo de mejora constante, acabas necesitando incrementos enormes de escala (del estilo multiplicar por 10), porque la ganancia marginal se va estrechando. Un ejemplo simplificado, basado en las leyes de escalado discutidas en los dos papers anteriores, lo ilustra bien:
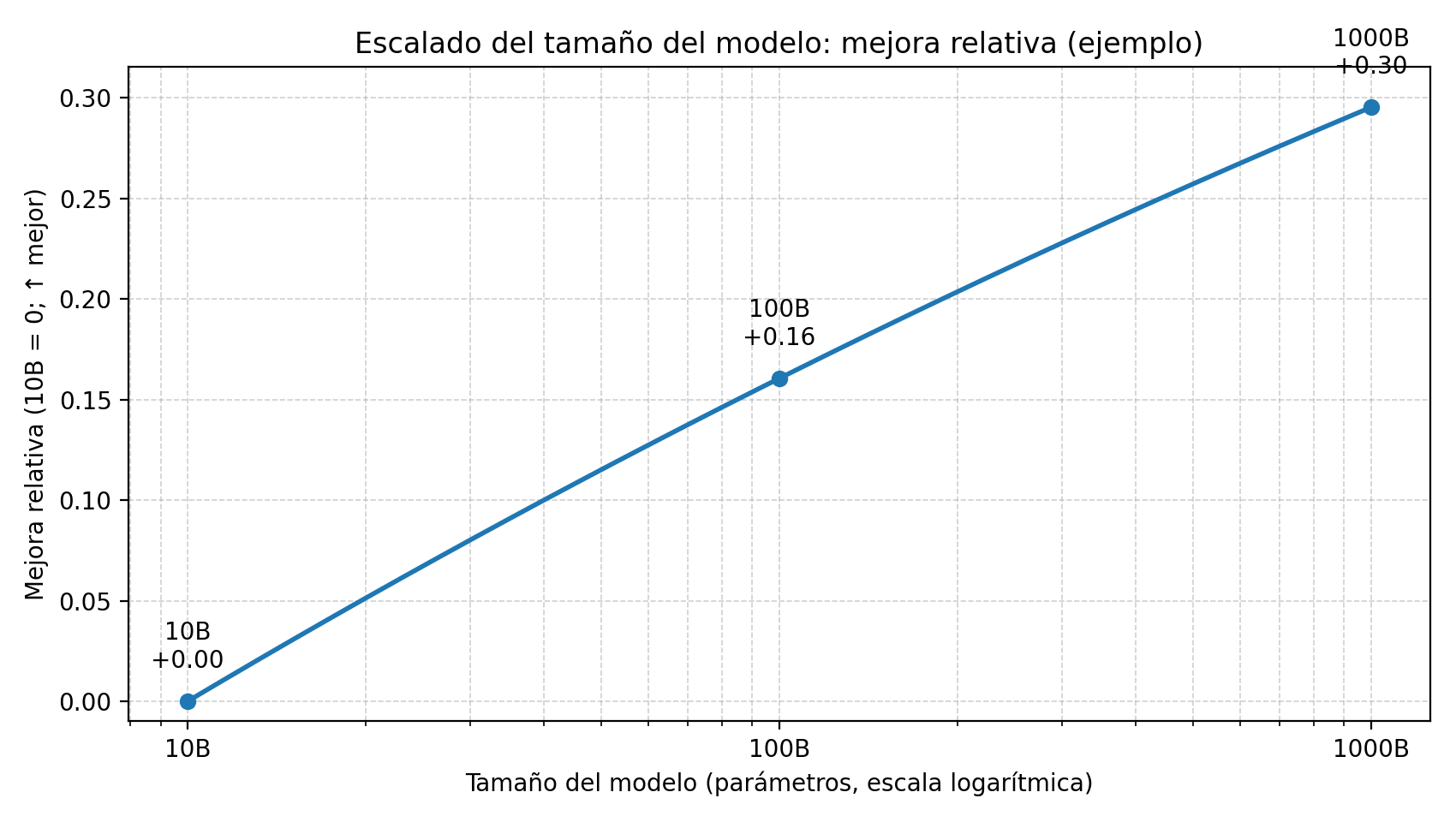 Figura 1. Ejemplo ilustrativo de scaling con eje X logarítmico (parámetros): para obtener incrementos de rendimiento de tamaño comparable, es necesario aumentar el tamaño del modelo por órdenes de magnitud (p. ej., 10B→100B→1000B).
Figura 1. Ejemplo ilustrativo de scaling con eje X logarítmico (parámetros): para obtener incrementos de rendimiento de tamaño comparable, es necesario aumentar el tamaño del modelo por órdenes de magnitud (p. ej., 10B→100B→1000B).
Conclusión clara: si el progreso dependiera principalmente de “más grande = mejor”, entonces sin saltos masivos de escala 2025 debería haber sido un año de mejoras pequeñas y caras, con sabor a estancamiento.
Qué paso en 2025
Y, sin embargo, no fue eso lo que vimos…
Durante 2025 se han seguido publicando nuevas versiones de los modelos principales. Las empresas se han visto inmersas en una carrera frenética de lanzamientos y muchas veces se han contraprogramado y pisado unas a otras para conseguir el foco de atención, como si estuviéramos hablando de grandes blockbusters de cine. Y los expertos y analistas de IA nos han bombardeado con pruebas, ejemplos y pantallazos de lo bien (o mal) que funcionan estos nuevos modelos. La industria y el fandom no ha parado en 2025.
Modelos comerciales
A finales de 2024, los principales modelos comerciales existentes eran los siguientes. Entre paréntesis se muestra el precio de output de 1M de tokens, también a finales de 2024.
- OpenAI: o1, GPT-4o ($15.00), GPT-4o mini ($2.00)
- Anthropic: Claude 3 Opus, 3.5 Sonnet ($15.00), 3.5 Haiku ($4.00)
- Google: Gemini 1.5 Pro ($10.00), 2.0 Flash ($0.40)
- xAI: Grok-2 ($10.00), Grok-2 mini
Un año después, a finales de 2025:
- OpenAI: GPT-5.2 ($14), GPT-5.2 Pro ($168.00), GPT-5.2-codex ($10.00), GPT-5-mini ($2.00), GPT-5-nano ($0.40)
- Anthropic: Claude 4.5 Opus ($25.00), 4.5 Sonnet ($15.00), 4.5 Haiku ($5.00)
- Google: Gemini 3 Pro ($12.00), 3.0 Flash ($3.00)
- xAI: Grok 4 ($15.00), 4.1 Fast ($0.50)
- Alibaba: Qwen3-Max ($6.00)
La mayoría de empresas ha subido en una unidad el número mayor de versión. Por ejemplo, OpenAI ha pasado de GPT-4o a GPT-5.2. Google de Gemini 2.0 Flash a Gemini 3.0 Flash.
Los precios por token no se han modificado demasiado, aunque se ha fragmentado más, lo que indica un mercado más maduro y especializado. A finales de 2024 se podían diferenciar dos capas, la alta, de unos $10 o $15 por millón de tokens de salida y baja, de unos $2 o $4. Un año después, estas dos capas se mantienen, pero han aparecido una capa por encima, los $168 de OpenAI con su GPT-5.2 Pro y otra de modelos muy baratos de ejecución, los $0.40/$0.50 de GPT-5 nano, Grok 4.1 Fast o Gemini 3.0 Flash.
Capacidades de los modelos comerciales
Hasta aquí hemos hablado de inputs (versiones, precios, segmentación). Para pasar a outputs (capacidad medida), voy a usar como indicador agregado (un “proxy”): una medida resumida que condensa varios benchmarks en un único número para tener una primera lectura global antes de entrar en pruebas concretas. En concreto, el Intelligence Index de Artificial Analysis (AA), una plataforma independiente que publica metodología y, sobre todo, ejecuta las evaluaciones por su cuenta (en lugar de depender de números auto-reportados por los laboratorios).
Si te interesa la “cocina” de estos números, aquí enlazo una entrevista (Latent Space) con George Cameron y Micah Hill-Smith, los creadores de Artificial Analysis. Explican por qué corren ellos mismos las evaluaciones (estandarizando prompts, evitando cherry-picking y controlando endpoints), su política de “mystery shopper”, y cómo construyen el Intelligence Index (v3/v4) agregando conjuntos de pruebas con repeticiones para estimar estabilidad.
https://www.youtube.com/watch?v=v5mBjeX4TJ8
El Intelligence Index v4.0 agrega 10 evaluaciones y devuelve una puntuación 0-100. La figura muestra una comparación explícita entre diciembre 2025 y diciembre 2024 con los resultados de los modelos mencionados anteriormente y muestra un desplazamiento claro al alza: la frontera pasa de 31 (o1) a 51 (GPT-5.2), y el grupo líder se mueve en bloque hacia arriba.
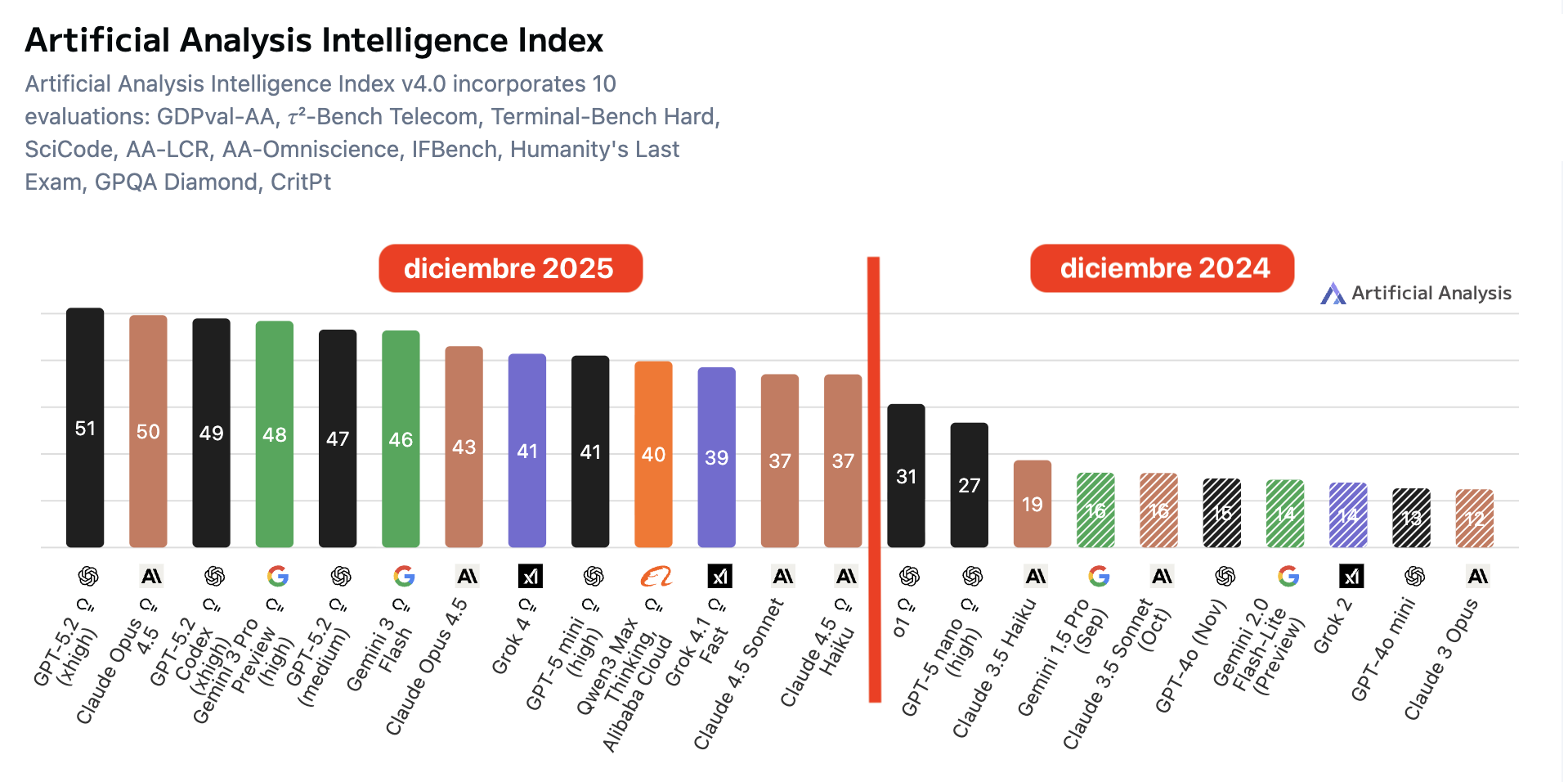 Pie de figura: Artificial Analysis Intelligence Index (v4.0): comparación de puntuaciones para modelos comerciales destacados en diciembre 2024 y diciembre 2025. El índice sintetiza resultados de 10 benchmarks en una escala 0–100; se observa un desplazamiento al alza de la capacidad medida (la mejor puntuación pasa de ~31 a ~51, y el grupo líder sube de forma consistente).
Pie de figura: Artificial Analysis Intelligence Index (v4.0): comparación de puntuaciones para modelos comerciales destacados en diciembre 2024 y diciembre 2025. El índice sintetiza resultados de 10 benchmarks en una escala 0–100; se observa un desplazamiento al alza de la capacidad medida (la mejor puntuación pasa de ~31 a ~51, y el grupo líder sube de forma consistente).
Modelos abiertos
¿Y qué ha pasado con los modelos abiertos? A diferencia de los modelos comerciales, en ellos sí que podemos analizar cómo ha cambiado su número de parámetros durante 2025.
Hay que hacer notar que en 2025 se han popularizado las arquitecturas tipo MoE (mixture-of-experts) que permiten activar solo un subconjunto pequeño de los parámetros del modelo, de modo que el cómputo por token se mantiene relativamente bajo aunque el número total de parámetros del modelo sea mucho mayor. Lo que mostramos entre paréntesis son los números totales aproximados de parámetros, que son los usados en entrenamiento y determinan la capacidad del modelo.
A finales de 2024:
- Alibaba: Qwen 2.5 (72B)
- Mistral: Mistral Large 2.1 (123B)
- NVIDIA: Nemotron-4 (340B)
- Meta: Llama 3.1 (405B)
- DeepSeek: DeepSeek-V3 (671B)
Y los principales modelos open source al final de 2025:
- OpenAI: gpt-oss (120B)
- Alibaba: Qwen3 (235B)
- xAI: Grok-1 (314B)
- NVIDIA: Nemotron 3 (Nano 30B, Super 100B, Ultra 500B)
- Mistral: Large 3 (675B)
- DeepSeek: DeepSeek R1, DeepSeek-V3.1 (671B)
- Moonshot AI: Kimi K2 (~1T)
- Zhipu AI: GLM-4.5 (130B)
Si hacemos una lectura gruesa, en un año no aparece un salto de orden de magnitud en tamaño. A finales de 2024 los modelos abiertos frontera tenían una media en torno a ~300B parámetros; a finales de 2025 están en torno a ~450B, aproximadamente un ~1.5× (≈50% más).
Capacidades de los modelos abiertos
Lo interesante es que, incluso sin 10× en parámetros, la capacidad medida de los mejores modelos abiertos sí se desplaza de forma clara. Usando el mismo Intelligence Index v4.0 de Artificial Analysis (mismo agregado de 10 evaluaciones): el máximo pasa de 16 (Qwen2.5 Max) / 15 (Mistral Large 2) a 42 (DeepSeek V3.2) y 41 (Kimi K2 Thinking). Es decir: un salto de ~+24 puntos en un año, con un pelotón de modelos abiertos ya por encima de 20–30 en la escala.
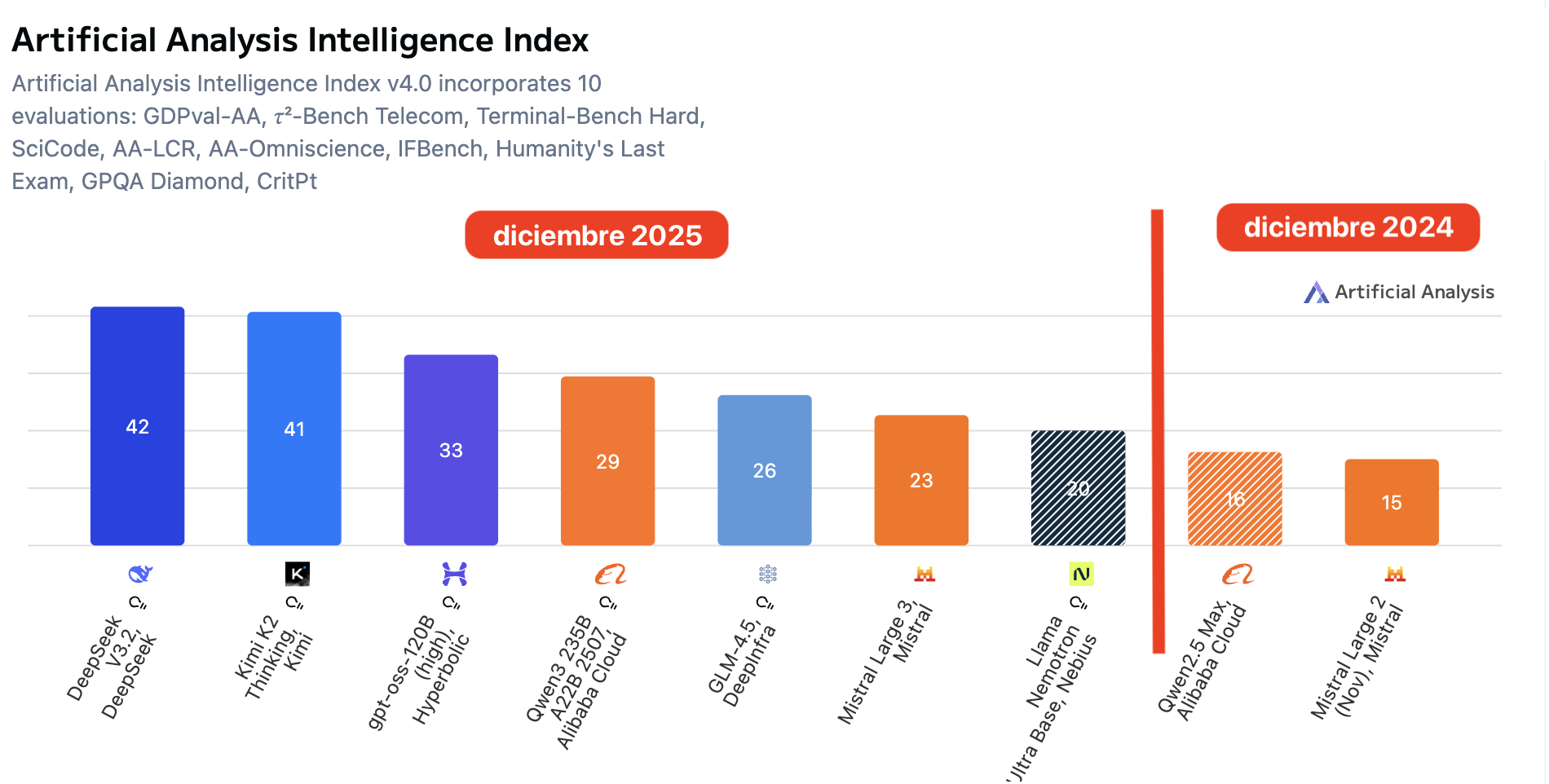
Pie de figura. Artificial Analysis Intelligence Index (v4.0) — modelos open-weights: comparación diciembre 2024 vs diciembre 2025. El índice agrega 10 benchmarks en una escala 0–100; la frontera open-weights sube de ~18 a ~42 y aparecen varios modelos en la franja 20–30+, indicando un desplazamiento sustancial de capacidad sin necesidad de 10× en tamaño.
¿Cuánto creció la escala en 2025?
Hemos visto que la capacidad medida sube. Antes de entrar en benchmarks concretos, merece la pena mirar la variable básica de la que hemos hablado al principio: ¿cuánto ha crecido la escala (el tamaño) de los modelos en un año? En los modelos abiertos se puede estimar; en comerciales, solo acotarlo con señales indirectas.
Modelos abiertos: aumento modesto de tamaño
¿Cómo se ha incrementado el tamaño de los modelos en un año? En cuanto a los modelos abiertos, hemos visto que no demasiado. A finales de 2024 los modelos abiertos tenían ~400B parámetros y a finales de 2025 ~600B, un ~1.5x. En absoluto se ha conseguido el 10x que según las leyes de potencia se necesitaban para mantener el ritmo de mejora.
Modelos comerciales: falta de datos y estimaciones razonables
En cuanto a los modelos comerciales no hay forma de saberlo directamente, porque hace mucho tiempo que los laboratorios no publican este dato en sus system cards. Algunas filtraciones hablaban de ~1.8T (1.800B) para GPT-4o, ~10x el número de parámetros de GPT-3 en 2020 (175B). Una especulación razonable es hablar de un orden de magnitud de ~1T (1.000B, un billón español) para el tamaño de los modelos frontera a finales de 2024.
¿Y a finales de 2025? Solo podemos especular. Podemos partir de declaraciones del propio Elon Musk comentando que Grok 4 tiene 3T parámetros. Estaríamos entonces en unos ~3x el tamaño de los modelos de un año antes, compatible con el ritmo de mejora de los modelos abiertos (el doble), pero muy lejos de los 10x de las leyes de potencia.
Inferencia: coste por token, MoE y “tamaño efectivo”
El precio de los tokens está relacionado con el coste de inferencia, que a su vez está debería estar relacionado con el tamaño de los modelos en ejecución. Teniendo en cuenta que la mayoría de modelos usa el Mixture-of-Experts (MoE) y que el factor de parámetros activados vs parámetros totales suele ser de entre ~2x y ~4x, si los costes de inferencia a finales de 2025 son similares a los de un año antes, entonces estamos hablando de modelos con un tamaño total de entre ~2x y ~4x el tamaño de los modelos de finales de 2024. Encaja con los 3T parámetros de los que habla Musk.
Como conclusión de todas las evidencias que hemos presentado, no parece un año de 10× en escala. Y, sin embargo, el Intelligence Index de AA sugiere que las capacidades agregadas han seguido aumentando de forma sustancial. La pregunta natural es si esa señal se mantiene cuando bajamos a tareas concretas (en lugar de un índice agregado). Vamos a comprobarlo con dos benchmarks donde el salto 2024→2025 es especialmente claro: ARC-AGI y SWE-bench.
ARC-AGI y SWE-bench
ARC-AGI
Empecemos por ARC-AGI, el test propuesto por Françoise Chollet que ya hemos comentado en esta newsletter, en el que el sistema debe inferir reglas/patrones a partir de rejillas de colores. (ARC publica resultados para dos variantes: ARC-AGI-1 y ARC-AGI-2, siendo esta última sustancialmente más exigente.)
Foto (marzo 2025). En el leaderboard del 24/03/2025 (recuperado vía archive.is) se observa que, entre modelos ampliamente desplegados y con costes razonables, la mayoría se mueve en torno a ~30% o menos en ARC-AGI-1. En esa fecha aparece también un sistema experimental de OpenAI, o3 (low), con 75.7% en ARC-AGI-1 pero a un coste de $200 por tarea, mientras que el modelo público más capaz de la tabla, o1 (high), marca 32.0% en ARC-AGI-1 y 3.0% en ARC-AGI-2 con un coste de $4.45 por tarea.
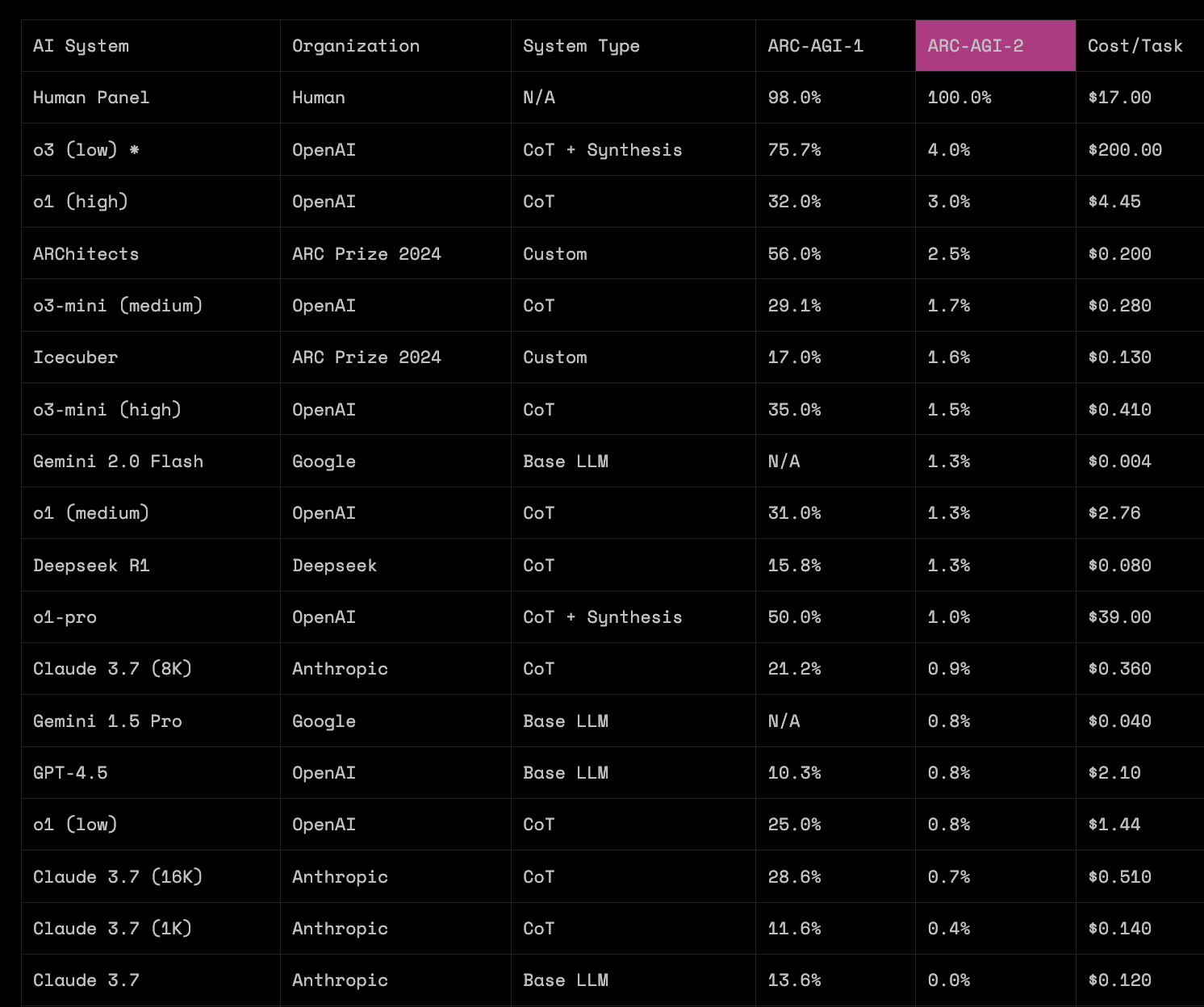
Foto (enero 2026 / cierre de 2025). Un año después, la situación cambia de forma sustancial. En la tabla actual, varios modelos frontera se sitúan en la franja alta de ARC-AGI-1, y el coste por tarea cae en órdenes de magnitud. Por ejemplo, GPT-5.2 (Medium) obtiene 72.7% en ARC-AGI-1 por $0.759 por tarea: rendimiento comparable al de o3 (low) en 2025, con un coste ~263× menor.
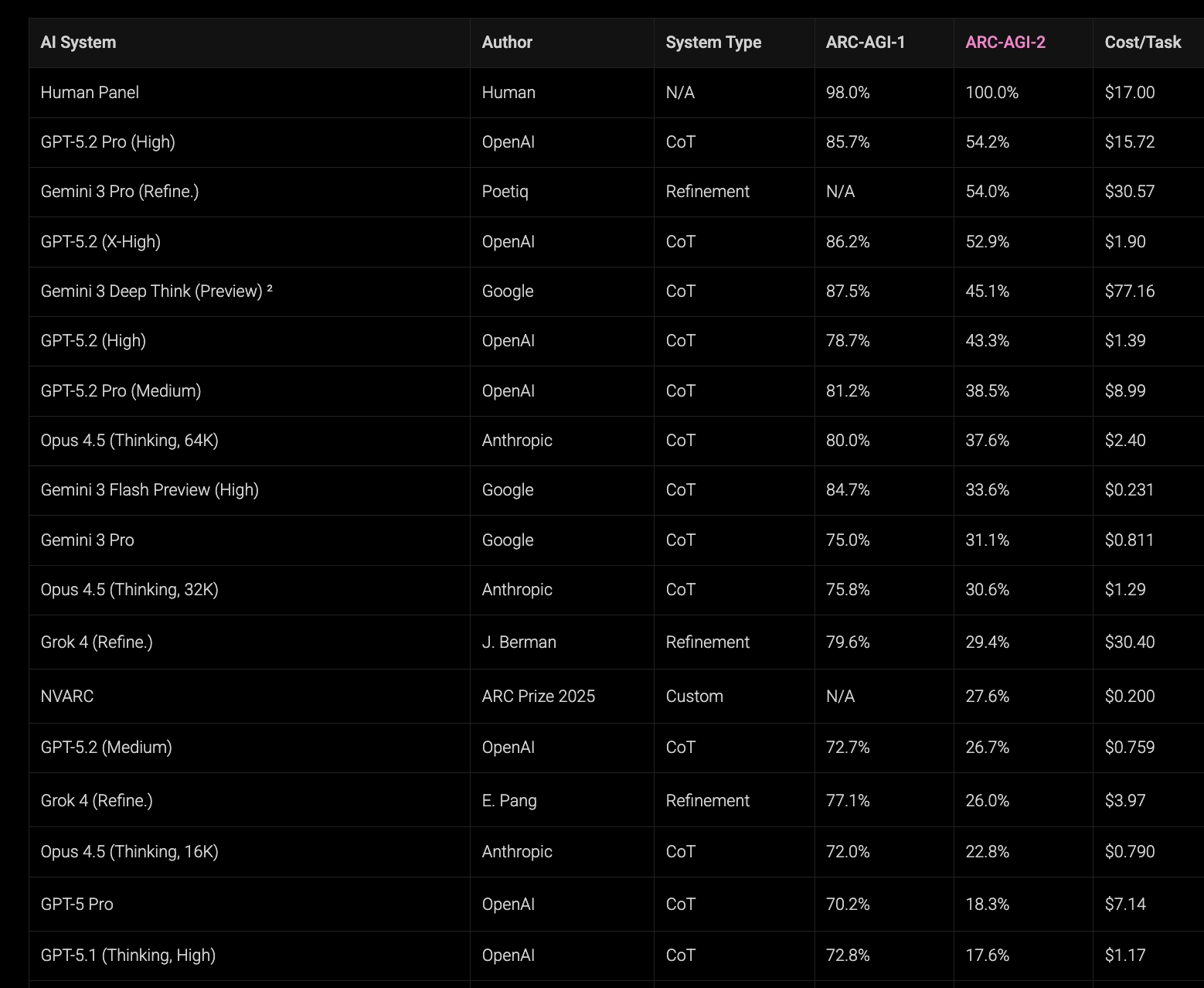
En ARC-AGI-2 el salto es todavía más claro: o3 (low) aparece con 4.0% en 2025, mientras que en la tabla reciente GPT-5.2 Pro (High) alcanza 54.2% con un coste de $15.72 por tarea.
Si fijamos un presupuesto por tarea del orden de $1–$2, el cambio también se ve con claridad: en 2025 esa zona estaba asociada a resultados alrededor de ~25% en ARC-AGI-1, mientras que en 2026 se observan resultados en torno a ~70–80% con costes similares.
La organización de la prueba presenta los resultados actuales de ARC-AGI-1 y 2 de una forma visual muy brillante, que permite comprobar de un vistazo el rendimiento-coste e identificar fronteras eficientes (qué modelos dominan para un presupuesto dado). Para comprobar el progreso que ha habido en el último año podemos jugar a buscar en estas figuras las posiciones de modelos de finales de 2024 (GPT-4.5 o Cluade 3.7) y compararlos con los modelos frontera actuales de su mismo precio (subir en vertical).
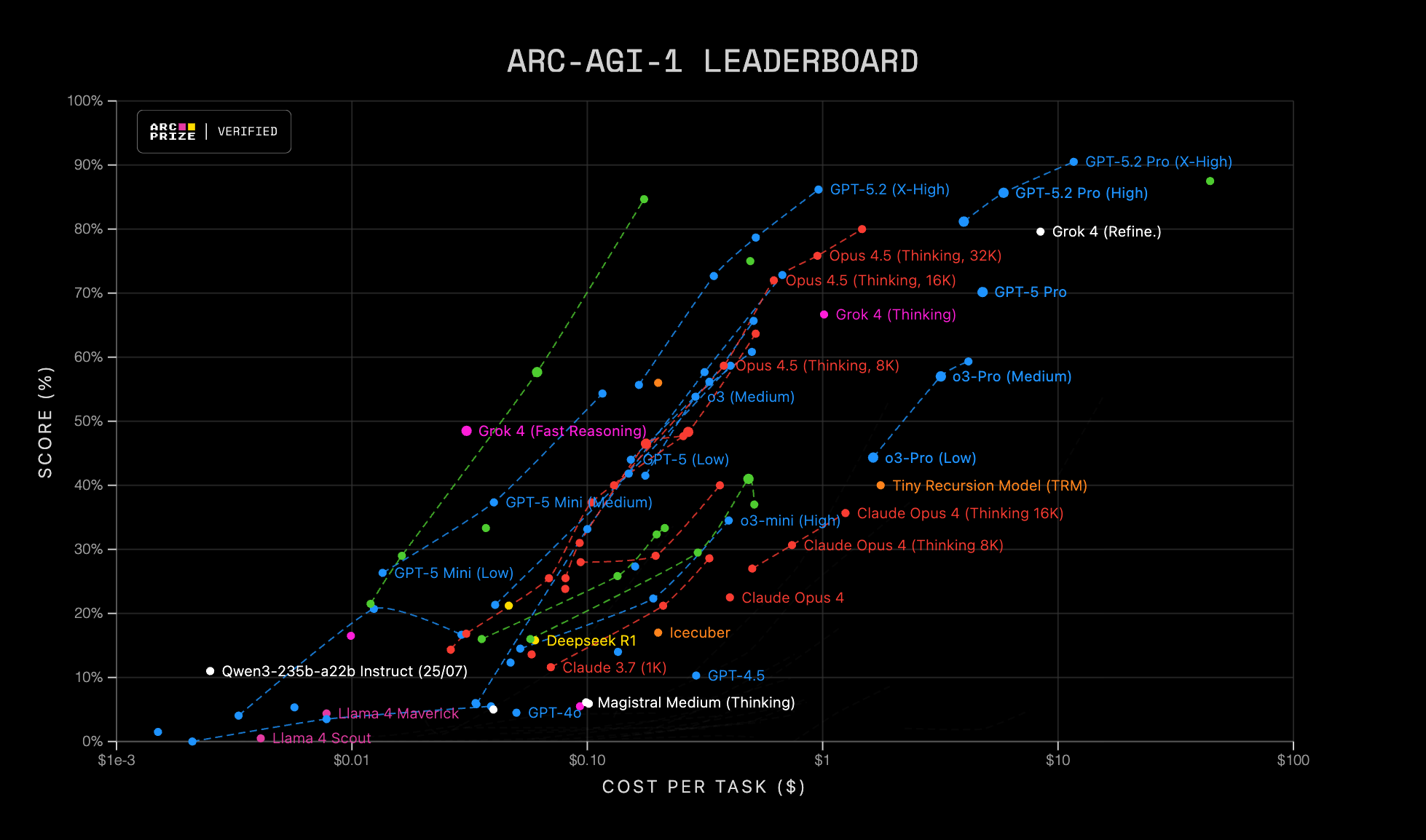
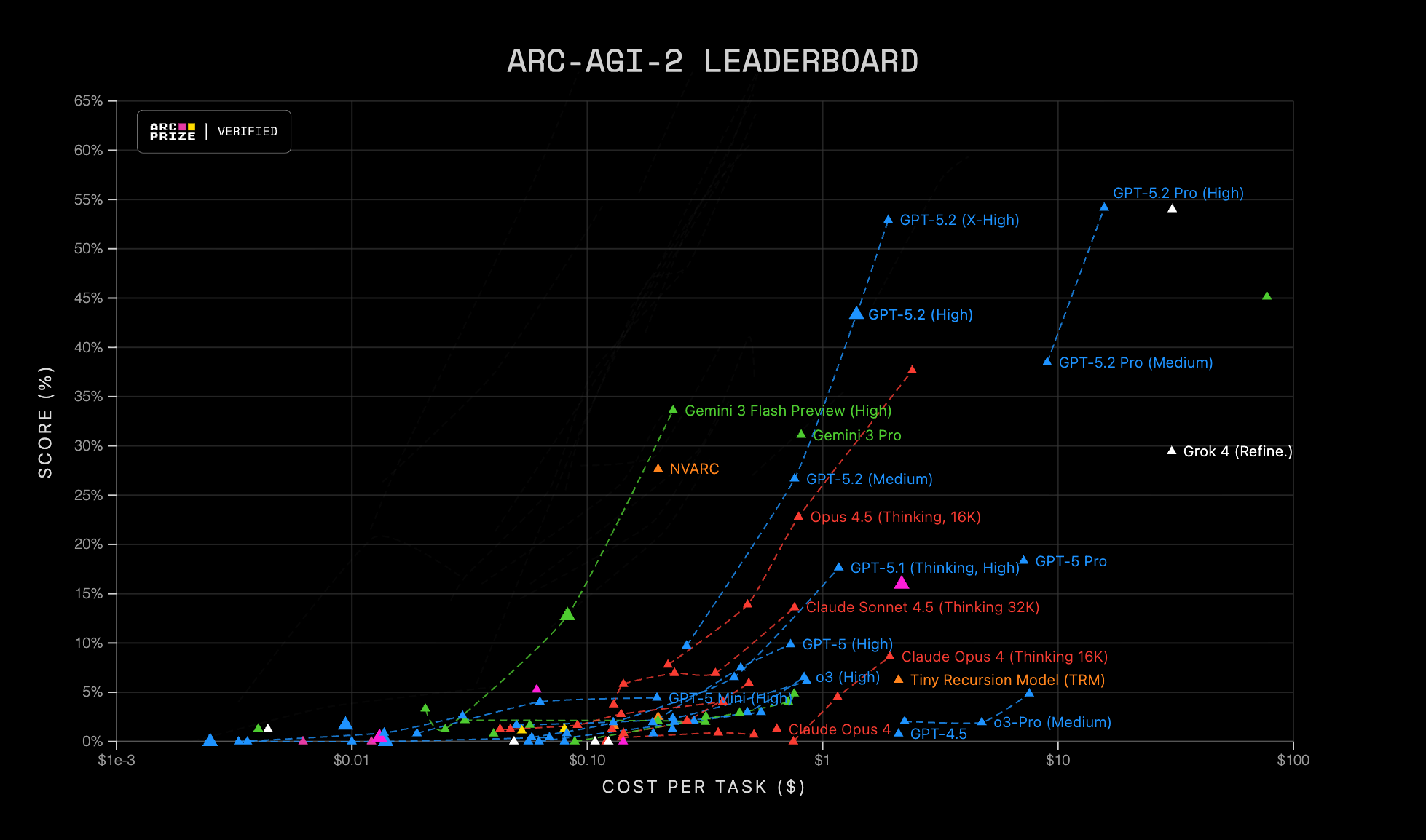 Pie de figura (ARC-AGI Leaderboard): Dispersión de score (%) frente a coste por tarea (USD) en escala logarítmica. Cada punto representa una configuración evaluada (modelo y modo/ajustes), y las líneas discontinuas agrupan variantes relacionadas. A la izquierda ARC-AGI-1 y a la derecha ARC-AGI-2.
Pie de figura (ARC-AGI Leaderboard): Dispersión de score (%) frente a coste por tarea (USD) en escala logarítmica. Cada punto representa una configuración evaluada (modelo y modo/ajustes), y las líneas discontinuas agrupan variantes relacionadas. A la izquierda ARC-AGI-1 y a la derecha ARC-AGI-2.
SWE-bench Verified
El benchmark SWE-bench Verified es también muy relevante y mide algo bastante distinto a ARC-AGI: no es inducción de reglas en rejillas, sino capacidad de ingeniería de software. El conjunto está formado por tareas reales extraídas de repositorios populares de Python. Cada ejemplo incluye un bug a resolver y una batería de tests. El objetivo del modelo es proponer un parche que haga que los tests vuelvan a pasar. No es un ejercicio de completar código en abstracto: obliga a leer y entender una base de código existente, localizar la causa del fallo, modificar los ficheros correctos y respetar convenciones, dependencias y efectos colaterales.
Es, además, un test que no está saturado. A finales de 2024, las mejores cifras públicas estaban en torno al 50%, normalmente obtenidas con agentes y capas de orquestación (scaffolds) relativamente complejas, basadas principalmente en Claude 3.5 Sonnet.
A finales de 2025 se entra en la franja del 70–75%. Y, lo más importante, esta tasa de éxito se consigue con una configuración con andamiaje mínimo: mini-SWE-agent, con ~100 líneas de Python, que esencialmente implementa un bucle de interacción con el LLM y ejecución de acciones. Esto reduce el peso de la orquestación externa y aproxima la evaluación a lo que nos interesa aquí: comparar capacidades del modelo con un scaffold simple y estandarizable, frente a 2024, donde una parte no despreciable del rendimiento dependía de agentes más elaborados.
La siguiente figura muestra el ranking de modelos con mejor rendimiento en SWE-bench Verified en el momento de la captura. Anthropic, Google y OpenAI lideran la clasificación con tasas de resolución superiores al 70%.
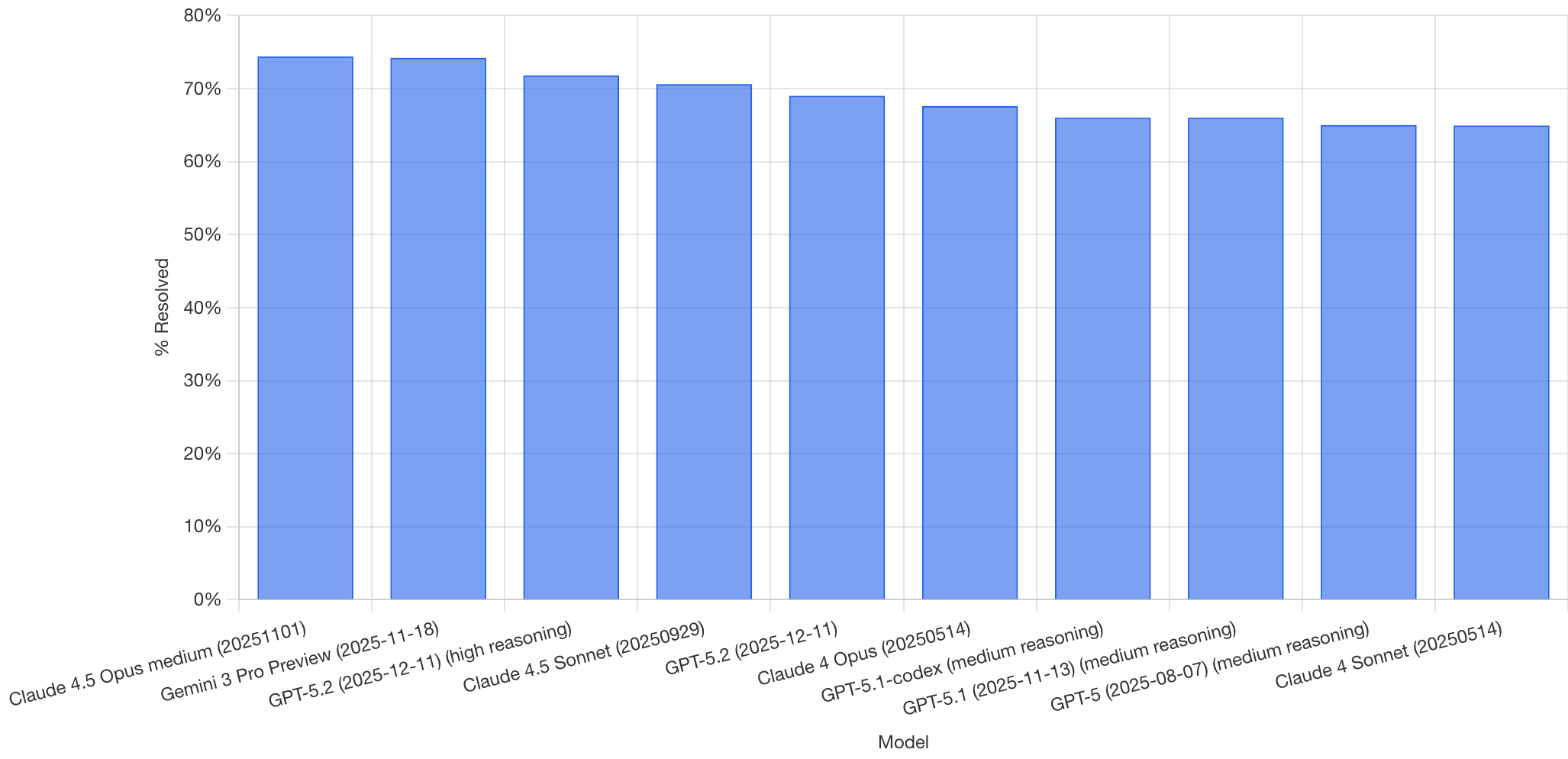
Pie de figura. SWE-bench Verified: porcentaje de tareas resueltas (% Resolved) por modelo. Cada barra corresponde a una variante evaluada (el eje X incluye el nombre del modelo y la fecha/versión reportada en la captura).
Ofir Press, uno de los creadores de SWE-bench, pronostica que a finales de 2026 se llegará al 86% de aciertos (en la configuración “SWE-bench Verified w/ mini-SWE-agent”).
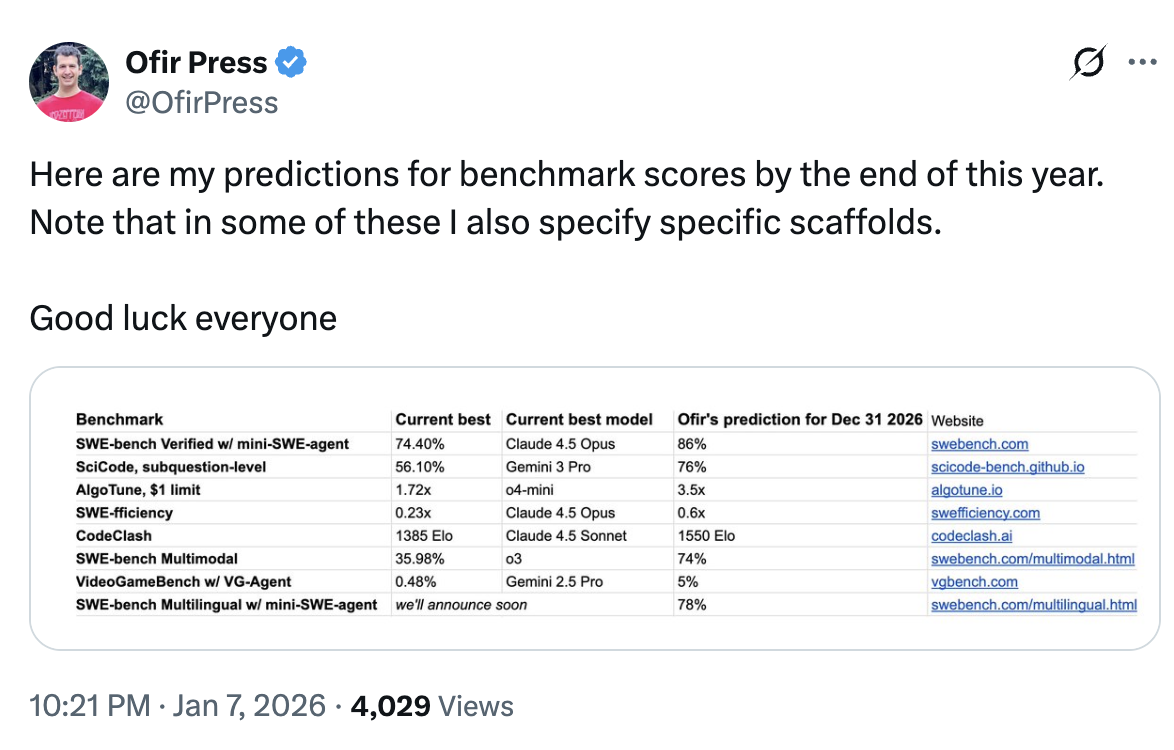
Pie de figura. Captura de la predicción de Ofir Press (enero 2026) con una tabla de “mejor resultado actual” y “predicción para 31 dic 2026”; en la primera fila se indica SWE-bench Verified w/ mini-SWE-agent: 74.40% → 86%.
¿Qué ha impulsado el salto de capacidad en 2025?
En 2025 se han observado mejoras sustanciales en los modelos sin un aumento proporcional de su tamaño ni del coste por token en inferencia. El número de parámetros parece haber crecido —en muchos casos, del orden de doblarse o triplicarse—, pero no ~10×, que es lo que una lectura simplificada de las leyes de escalado sugeriría para mantener un ritmo de mejora “lineal”.
Una de las razones por las que no ha habido un incremento grande y generalizado en tamaño podría ser la disponibilidad limitada de nuevo hardware durante buena parte del año. Sabemos que muchos modelos de 2024 se entrenaron principalmente con GPUs Hopper, en particular H100. Por ejemplo, Llama 3.1 (405B, finales de julio de 2024) se entrenó a escala de >16K H100 durante varios meses. La plataforma Blackwell (B200/GB200) inició su rampa de despliegue a partir del segundo trimestre de 2025 y requiere cambios relevantes de infraestructura, por lo que es razonable suponer que una fracción significativa del ciclo de entrenamiento de 2025 todavía dependió de Hopper.
Y, sin embargo, el rendimiento ha seguido subiendo. Los laboratorios han publicado nuevas versiones y los benchmarks han mejorado de forma clara. En particular, ARC-AGI-1 se puede considerar resuelto, y SWE-bench Verified sube desde valores alrededor del 50% (con scaffolds complejos) a la franja ~70–75% con andamiaje mínimo.
¿Cómo se consigue esta mejora con escala moderada?
(1) Optimización de inferencia y eficiencia. En 2025 se han exprimido las capacidades mediante mejoras en inferencia: estrategias de uso de tokens, presupuestos adaptativos, y configuraciones más eficientes. Además, se han usado técnicas de destilación para transferir capacidad a modelos más pequeños, reduciendo coste sin perder demasiado rendimiento.
(2) Arquitecturas más eficientes (MoE). El uso de Mixture-of-Experts (MoE) permite aumentar parámetros totales sin aumentar proporcionalmente el cómputo por token, activando solo una fracción del modelo en cada paso. Esto facilita mejorar rendimiento manteniendo coste operativo.
(3) Razonamiento explícito (Chain-of-Thought) y control del cómputo de test-time. El avance más visible de 2025 ha sido la generalización de modelos “razonadores” basados en Chain-of-Thought (CoT). OpenAI lo popularizó con o1 (finales de 2024) y, poco después, DeepSeek publicó una implementación abierta. A finales de 2025, prácticamente todos los laboratorios ofrecen variantes razonadoras. La consecuencia técnica es importante: la capacidad observable no depende solo de la “respuesta inmediata” (System 1), sino también del cómputo de test-time invertido en una traza de razonamiento (System 2): planificación, verificación de pasos, corrección y reintentos.
(4) Agentes y herramientas: aprendizaje de políticas de uso. CoT ha sido también un componente clave para agentes que usan herramientas de forma controlada (búsqueda, ejecución de código, manipulación de ficheros). Para que esto funcione, el modelo debe aprender cuándo usar una herramienta, cómo formular la llamada y cómo incorporar el resultado en su plan.
(5) Post-training con aprendizaje por refuerzo (RL) a gran escala. Para afinar capacidades más allá del pre-training, 2025 consolida el uso de RL en post-training. OpenAI popularizó RLHF (reinforcement learning from human feedback), pero el feedback humano limita la escala y la longitud de las trayectorias. En 2025 se generalizan esquemas donde la señal de refuerzo proviene de verificadores automáticos (en tareas con solución comprobable) y de LLMs como jueces en tareas no triviales. Esto permite trayectorias más largas y entrenamiento más extensivo de habilidades System 2: planificación, verificación y uso de herramientas.
El resultado de 2025 es que el progreso deja de estar gobernado exclusivamente por “más grande = mejor”. Con escala moderada, la combinación de eficiencia (inferencias y arquitecturas), razonamiento explícito, agentes y post-training con RL es suficiente para producir mejoras grandes y medibles.
Escalado e innovación: el patrón de 2025
En 2025 no hay señales de “muro”. Lo que se observa es que el escalado sigue siendo importante, pero no actúa solo: el progreso viene de combinar escalado con técnicas que aumentan la capacidad efectiva por unidad de cómputo (tanto en entrenamiento como en inferencia).
En palabras de Demis Hassabis, al hablar sobre los avances recientes de DeepMind:
Esa combinación [de innovación y escalado], creo, nos permite estar en la frontera tanto de la innovación como del escalado. En la práctica, puedes pensar que aproximadamente el 50% de nuestro esfuerzo está en el escalado y el otro 50% en la innovación. Y mi apuesta es que vas a necesitar ambas cosas para llegar a la AGI.
Si 2024 fue el año en que se consolidó la idea de que “razonar cuesta tokens”, 2025 es el año en que la industria aprende a convertir ese coste en rendimiento medible: mejores políticas de inferencia, mejores arquitecturas y post-training más sistemático. El escalado no desaparece; pero, para explicar el salto de 2025, hay que mirar también a la innovación.