o3 solves ARC-AGI
When I sent out my last article earlier this week, I thought it would be the last one of the year. I wanted to end the year talking about the dogma of deep learning, opening the way for a future follow-up on consciousness. I also wanted to leave the newsletter alone for a few weeks and work slowly and calmly on that new piece.
In fact, I have changed the title of the newsletter: it is no longer called Fifteen Days. That takes away the pressure of having to publish twice a month and cover current events. There are already many very good AI news newsletters. I want to continue with the approach of the most recent issues, where I go into some depth on a topic that does not necessarily have to be news-driven.
But on Friday something happened that has to be covered here, no matter what.
OpenAI has released extremely impressive results for its new reasoning model o3, the next version after o1. The presentation video is below:
All the results they show point to a spectacular leap on the hardest benchmarks. For example, they go from 48.9% to 71.7% on SWE-bench Verified, a benchmark of programming problems. And they also go from 3% to 25% on Frontier Math, a test made up of PhD-level mathematics problems.
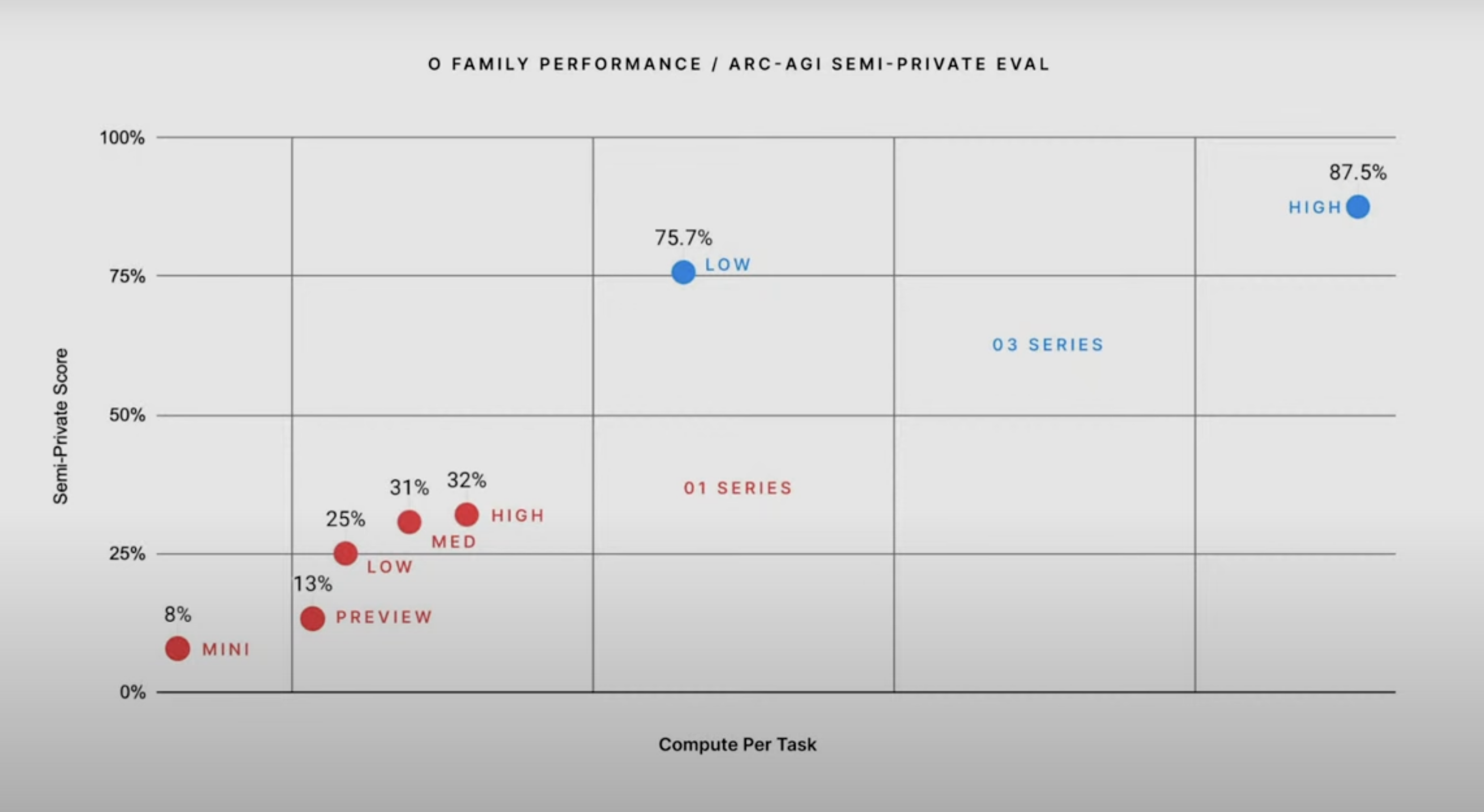
But what was truly surprising is that they managed to solve François Chollet’s ARC-AGI competition. In the o3 launch video they showed the figure above, where o3 reaches 75.7% in its “low” version and 87% in its “high” version.
What do “low” and “high” mean here? As we saw in the article where we talked about how o1 works, these reasoning models can refine their results when they are given more compute time. “Low” and “high” are the names OpenAI researchers use for o3 with a smaller or larger inference-time compute budget. The chart also shows that the compute time of o3 low is significantly higher than that of o1 high, which only gets 32% (they do not say whether the horizontal axis is linear or logarithmic; I assume it is linear, like the vertical one).
The moment Greg Kamradt, president of the ARC Prize, appeared in the OpenAI stream and explained all this, my mind was blown. I could hardly believe it. I ran to X to check reactions, started reading posts from people close to the competition, and finally, when I saw Chollet’s own reaction, I knew it was real. The OpenAI team behind the “o” models had done something historic: solve ARC-AGI. In just three months, since the presentation of o1, they had solved a challenge designed to reveal reasoning ability and human-like intelligence.
What does this enormous success of o3 imply?
The most important implication is that it validates the approach behind the “o” family of reasoning models, and shows that these models successfully integrate the intuition of traditional LLMs (System 1) with some kind of deductive, iterative System 2 reasoning. OpenAI has found the ingredients of the definitive recipe, the one that combines the two kinds of reasoning we discussed in the article on Chollet. That combination is crucial for the future, because it guarantees continued progress. On the one hand, when a better intuitive model appears (GPT-5), it will be easy to plug it into the new “o” model. On the other hand, as deductive capabilities improve and compute becomes cheaper, we should also get major gains.
Another key implication is that this confirms the role of NVIDIA and of chip manufacturers in general. And of the energy needed to power them. Whoever has more megaFLOPS will get the best results. Ilya Sutskever has just said that data is the new fossil fuel. Compute power is too.
Finally, it is worth highlighting OpenAI’s enormous luck, or excellent execution. They were able to end the year with a spectacular breakthrough and found, with the “o” models, a way to keep moving toward AGI without relying on their next GPT model. Today, in the Wall Street Journal, there is a detailed report on the problems they are having in developing GPT-5. It seems that the two or three pre-training runs OpenAI has attempted have failed after months of computation. A model ten times larger than GPT-4 also needs ten times more data, at a minimum, and they seem to be struggling with that. The debate over whether there is a wall in deep learning is still unresolved.
It is also worth clarifying that, although o3’s success has been spectacular, we have not reached AGI yet. There are still many missing ingredients in these models, such as the ability to reason with a physical model of the world, continual learning, or creativity.
We will keep a very close eye throughout 2025 on these foundational research issues around deep learning and language models, because they will shape the future of technology.
In the meantime, the advances we have seen in 2024 already enable many applications that are still waiting to be built with the models we already have.
This is not slowing down.
See you next time.