François Chollet (#20 of 2024)

François Chollet on MLST
Last November 6, the podcast Machine Learning Street Talk published a fascinating interview with François Chollet. It is a conversation lasting more than two and a half hours in which Chollet revisits topics ranging from technical matters, such as how LLMs work and how they differ from AGI, to philosophical and social questions about AI, such as the emergence of consciousness in children or the existential danger associated with AI.
I have already written about Chollet several times here. For example, in this post I discussed his interviews with Dwarkesh Patel and Sean Carroll. There we saw that he is someone with a very strong technical background, he is the creator of Keras, the library for neural networks, and the author of the book Deep Learning with Python, whose opinions carry a great deal of weight in the LLM community. That is true both because of his paper On the Measure of Intelligence and because of the current ARC competition, which we also discussed here.
Today I want to go through that November 6 interview in some detail. Besides the podcast, it is also available on YouTube, where it has already passed 40,000 views.
In this article I will extract and comment on a number of quotes from the interview. Given how long the conversation is, I have had to make a substantial selection, focusing on the parts that interested me most. So this is, inevitably, a rather biased article. But I have not changed the meaning of Chollet’s remarks at all. Not everything he said is here, but everything that is here is something he did say.
If you want more technical detail on the topics discussed here, you can also check the talk that Chollet and Mike Knoop, the other organizer of the ARC competition, prepared for a university tour presenting the challenge:
System 1 and System 2 intelligence

ChatGPT-generated image.
The theory of System 1 and System 2, proposed by Daniel Kahneman in his book Thinking, Fast and Slow, describes two modes of thought that operate in the human mind. System 1 is fast, automatic, intuitive, and emotional. It works subconsciously and relies on pre-existing patterns to make decisions without conscious effort. System 2, by contrast, is slow, deliberate, logical, and analytical. It activates when we need to focus, solve complex problems, or make important decisions that require careful analysis.
This theory has had a strong impact on Chollet, who believes LLMs can easily implement System 1, but not System 2.
Deep learning models are excellent at producing results that are directionally accurate, but not necessarily exact. They are very good at generating useful suggestions. The System 1 process is similar to what LLMs do. They also rely on pattern matching and mechanisms akin to intuition.
For Chollet, unlike System 1, we can understand how System 2 works through introspection:
Introspection can be very effective for understanding how your mind handles System 2 thinking. It is not nearly as effective for System 1, because System 1 operates unconsciously and instantaneously, in parts of the brain to which you do not have direct access. It happens below the surface, outside conscious observation.
System 2, by contrast, is deliberate, slow, and low-capacity. Only a few things happen at any given moment, and it is inherently introspective.
How the mind works when operating in System 2 mode is similar to the step-by-step execution of a program. It is what we do, for example, when we sort a list of numbers or mentally add two long numbers: we run an algorithm we have learned.
Your thoughts exist in your mind in the form of programs.
Chollet argues that a fundamental feature of intelligence is the ability to execute those programs mentally, verify whether they work, and solve a new task by selecting and combining the best ones:
When you face a new task, you can mentally describe it using a set of properties and then generate a small number of hypotheses about programs that satisfy those descriptive constraints. You then test those hypotheses mentally to verify whether your intuition is correct. That is a classic example of System 2 thinking: it is, essentially, how program synthesis works in the brain.
The limits of deep learning

Slide from the ARC Prize 2024 University Tour.
When Chollet started working with deep neural networks, he thought they would be as powerful as Turing machines and could implement generic algorithms. After spending years trying to use them for automated theorem proving, he realized that their operation was based on pattern recognition.
At first, Chollet believed deep learning could achieve anything:
I, like many others in the field, assumed that deep learning models were a general computational substrate capable of performing any type of computation. I believed they were Turing-complete. Back in 2015 and 2016, similar ideas were widely discussed, such as the concept of neural Turing machines. There was a general sense of optimism that deep learning might eventually replace hand-written software altogether, and at first I subscribed to that view.
But then the problems appeared, when he tried to use deep learning for automated theorem proving. Neural networks only operated through pattern recognition; they were not able to execute discrete sequential programs:
I worked on automated theorem proving using deep learning together with Christian Szegedy. The key idea behind that work was that theorem proving is similar to program synthesis, since it involves a tree-search process guided by operators and axioms. Our goal was to use a deep learning model to guide that search.
I spent a significant amount of time exploring that approach and trying many different ideas. Although the results were better than chance, a deeper analysis showed that the gains came from superficial pattern recognition rather than genuine System 2 reasoning. The models were not learning general discrete programs; they were simply exploiting a shortcut based on pattern recognition that was always available. I saw that as a major obstacle. No matter how much I tweaked the architecture, the training data, or other elements, the models always tended to fall back on those shortcuts.
Pattern recognition was not enough to perform automatic deductions. Chollet concluded that for that we need to synthesize discrete algorithms:
This was a turning point for me. These models were, in essence, pattern-recognition engines. To reach System 2-like reasoning, something else was needed: program synthesis.
A speculative aside: Srinivasa Ramanujan, a System 1 mathematical genius?
Chollet’s ideas about the need for System 2 reasoning and the limits of System 1 are shared by almost the entire community. Even so, one question occurs to me: what are the limits of pattern recognition? Could we build an intuitive system that generates mathematical theorems? We do have one case that seems to suggest so: the Indian mathematician Srinivasa Ramanujan.
.jpg)
The brilliant Indian mathematician Srinivasa Ramanujan.
Srinivasa Ramanujan (1887-1920) was a self-taught genius who grew up in India and, despite having limited access to formal education in advanced mathematics, developed astonishing results in areas such as number theory, continued fractions, and infinite series.
According to those who worked with him, such as the British mathematician G. H. Hardy, Ramanujan arrived at results in a deeply intuitive way, almost as if they simply “appeared” in his mind. He often presented formulas and theorems directly, without providing formal proofs or the usual intermediate steps.
Ramanujan described his mathematical intuitions as a kind of divine inspiration, and attributed his ability to the Hindu goddess Namagiri, whom he considered his spiritual guide. Many of his formulas about continued fractions, infinite series, and elliptic functions seem to have been “intuited” without relying on conventional tools of calculation or step-by-step mathematical deduction.
Perhaps this goddess was nothing more than the enormous pattern-recognition capacity in Ramanujan’s mind, after training on a vast number of deductions.1
Combining System 1 and System 2

ChatGPT-generated image.
Chollet believes that, in our minds, System 1 and System 2 work simultaneously. Intuition points deduction in promising directions and discards options that do not look reasonable.
It is important to remember that System 2 does not operate in isolation. There is always a component of System 1 supporting it. I am convinced that no cognitive process in the human mind is purely System 1 or purely System 2. Everything is a mixture of both. Even in tasks that look heavily reasoning-centered, such as solving ARC, doing mathematics, or playing chess, there is a significant amount of pattern recognition and intuition involved.
For example, when solving an ARC task, you might consider only two or four hypotheses, despite the immense space of possible programs, which could include hundreds of thousands. What reduces that space to only a few viable options? Intuition, or pattern recognition, which is the job of System 1.
In another part of the interview, he emphasizes that LLMs are very good at intuitive search over large combinatorial spaces:
This process is similar to what LLMs do. They also rely on pattern matching and a kind of intuition to explore vast spaces and reduce them to a manageable number of possibilities. Although their results still need to be verified, their guesses are often surprisingly accurate. I think this reduction process is a fundamental aspect of cognition itself.
This may be one path toward building more advanced systems, by combining an LLM with an external verifier.
That is why combining an LLM with an external verifier is so powerful. It helps navigate the combinatorial explosion involved in testing every possible solution and, at the same time, compensates for the limitations of LLMs, which are primarily based on System 1 thinking. With an external verifier, you add a layer of System 2 reasoning to the critical final verification step, ensuring that the final solution is robust and reliable.
This resembles what o1 may be doing at inference time, except that in o1 the external verifier is itself another LLM.
For example, this is basically how DeepMind built AlphaGo, its superhuman Go system. It used a combination of neural networks for fast heuristic predictions, analogous to System 1, and Monte Carlo tree search to evaluate and verify moves more thoroughly, an approach closer to System 2. The neural networks predicted the most promising moves and estimated the probability of winning from a given board state, while the search procedure explored those moves in depth and expanded the most promising branches. That design allowed AlphaGo to combine pattern-based intuition with painstaking analysis, showing how the interaction between System 1-like and System 2-like processes can efficiently solve problems with very high combinatorial complexity.
Interpolation with value-centric abstractions
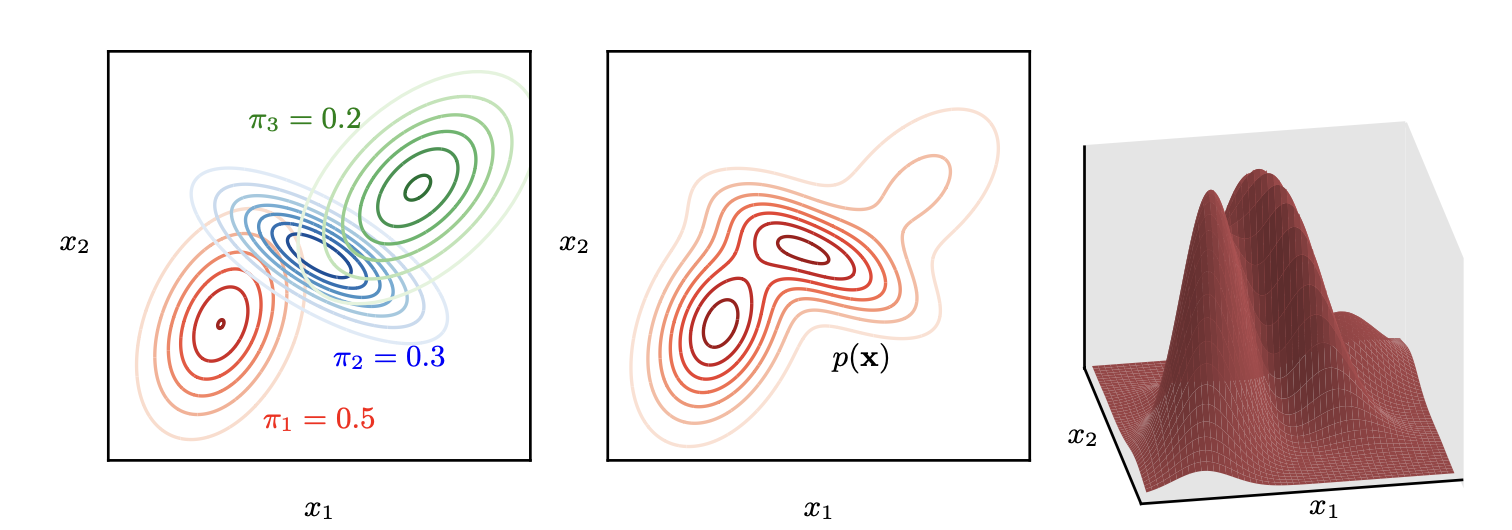
Illustration of a mixture of three Gaussians in a two-dimensional space, taken from Christopher M. Bishop’s book Deep Learning - Foundations and Concepts.
In the interview, Chollet mentions the concept of value-centric abstractions while discussing the limitations of the techniques used by deep learning, curve fitting and gradient descent in particular. The idea appears in this quote:
I think fitting parametric curves or using gradient descent works well for what I call value-centric abstraction. This idea is based on comparing elements using a continuous distance, which naturally leads to embedding those elements, such as images, discrete concepts, or words, in a manifold. In that manifold, similar elements are placed close to one another, and the different dimensions of variation inside that space acquire semantic meaning.
Chollet contrasts this with program-centric abstraction, explaining that while value-centric abstraction works well with continuous distances and similarities, it is not well suited for working with graphs and programs. As he puts it:
Curves are well suited to this kind of abstraction because they inherently encourage comparisons based on continuous distances.
These functions are created by the LLM during training as a way of predicting the next token. So the LLM does more than memorize; it is able to learn these kinds of curves or functions:
LLMs are trained to predict the next token using highly flexible and rich models. In theory, if they had infinite memory capacity, they could behave like a huge lookup table. In practice, however, LLMs are limited by having only billions of parameters. That limitation forces them to compress the information they learn rather than memorizing every sequence in the training data. What they are really learning are predictive functions, which take the form of vector-valued functions, since LLMs fundamentally operate over vectors. […] Those functions can generalize the training data to some extent.
And when we query an LLM, it can interpolate between those functions, combine them, and compose them:
When you query an LLM, you are essentially querying a point in function space. You can think of the LLM as a manifold where each point encodes a function. Moreover, you can interpolate through that manifold to compose or combine functions, which gives you an infinite number of potential programs to choose from.
Recent papers, such as Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics, reinforce these ideas and show how LLMs can solve mathematics problems using heuristics that result from combining pattern recognition.
Chollet acknowledges that the functions learned during pre-training can reach a high level of abstraction and capture abstract elements of language, such as Shakespeare’s literary style:
For example, imagine an LLM encountering Shakespeare for the first time. If it has already learned a general model of English, it can reuse much of that knowledge to understand Shakespeare. The text may be somewhat different, but it still fits the same underlying structure of English. The model can then learn a style-transfer function that adapts its general understanding of English in order to generate text in Shakespeare’s style. That is why LLMs are capable of tasks such as textual style transfer.
ARC, novelty, and the ability of intelligence to handle new situations
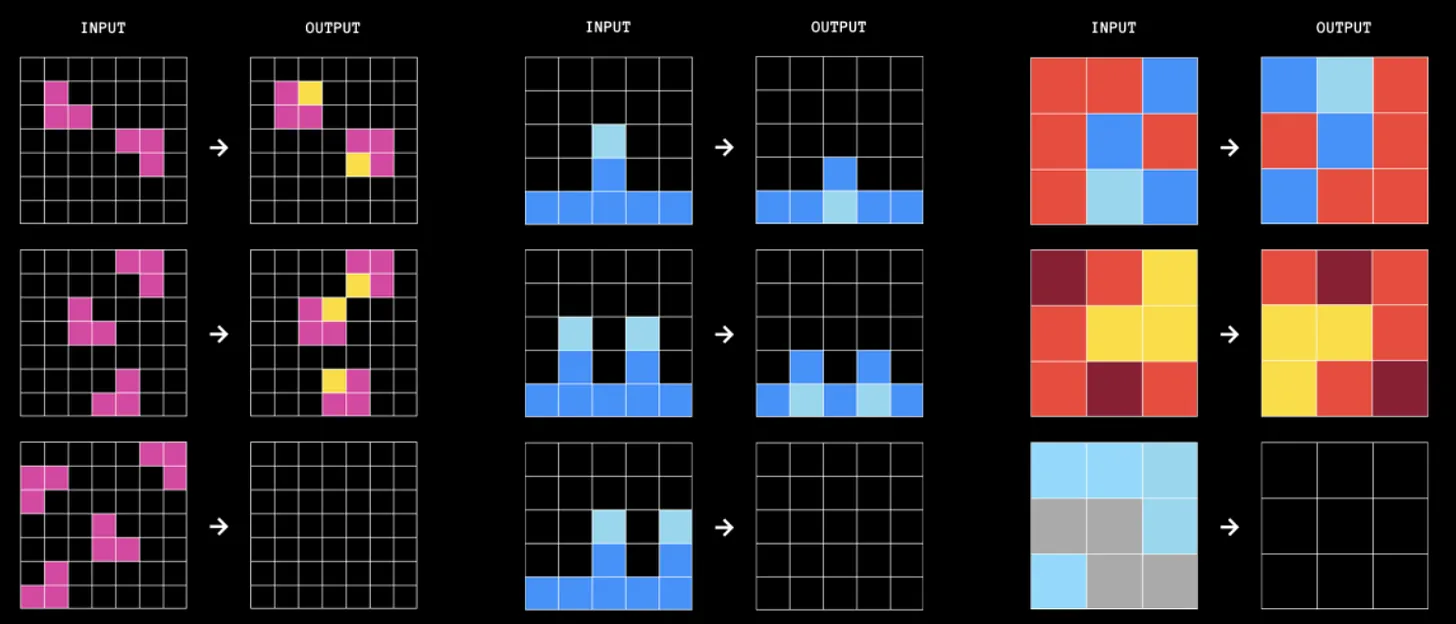
Example of ARC tasks.
Chollet considers one of the main features of human intelligence to be its capacity to handle novel situations and to do so from very few examples:
If you want to measure intelligence, you need to evaluate how efficiently the system acquires new skills with a limited amount of data.
The way to handle novelty is by creating new skills.
Intelligence is not just a skill; it is a meta-skill, the capacity by which you acquire new skills. Intelligence is, in essence, efficiency in skill acquisition.
And, most importantly, those new skills must be created in real time. In the case of LLMs, they should be created during inference time, not during pre-training. And this is precisely what LLMs cannot do:
If you ask them to solve problems that are significantly different from anything in their training data, they will generally fail.
So one of the main goals of ARC is to measure that ability to confront novelty:
If you want to measure intelligence, you need a different kind of test, one that cannot be beaten through prior preparation. ARC is such a test.
GPT-3.5, when used with direct prompting, achieves about 21% accuracy on ARC. This implies that around 80% of the dataset is genuinely novel, even compared to the entirety of the internet. That is a good sign of the benchmark’s robustness.
To solve an ARC task, we must build transformations, effectively programs, that turn an input image into an output image. These transformations use previously learned concepts such as number, position, or color. It is like using existing building blocks and combining them. But to do that we need to be able to execute trials and checks mentally, and that is precisely the ability LLMs lack:
In each ARC task, you are given between two and four demonstration examples, each composed of an input image and an output image. Your job is to identify the transformation or program that connects the input to the output. After learning that program from the examples, you are given a new input grid and must produce the corresponding output grid to demonstrate your understanding.
The main bottleneck here is the combinatorial explosion of the program space. The number of possible programs grows exponentially with the number of building blocks and with program length. If you search for programs involving, say, 40 function calls, the space becomes astronomically large, making exhaustive iteration impossible.
Humans, however, do not face this problem in the same way. When you tackle an ARC task, you execute only a small number of candidate programs step by step, mainly to check whether they are correct. This process relies on an extremely powerful form of intuition that dramatically reduces the search space. That intuition is not fully reliable, which is why you still need verification, but it is directionally correct. It steers you toward promising possibilities in what would otherwise be an overwhelming space of options.
The week of December 10 to 15, at NeurIPS 2024, the winners of this year’s competition will be officially presented and the prizes will be awarded: $50k to the best 5 teams and $75k to the 3 best conceptual papers. A paper summarizing the best advances and the source code of the most important contributions will also be released. The competition has already closed and nobody reached the $600k prize for solving 85% of the tests, but there has been real progress and the two best teams achieved 55.5% and 53.5%. We will talk more about that here.
AGI

ChatGPT-generated image.
To finish, let’s look at Chollet’s views on AGI, which are fairly optimistic. What stands out most to me is his separation between AGI and agency. AGI does not come with goal-setting attached to it. For Chollet, that is something external to AGI itself. I completely agree.
AGI will be achieved, but it will be just a tool:
For me, building AGI is a scientific endeavor, and once developed it will be a highly useful tool, nothing more. AGI will be, as I said earlier, a path-search algorithm for navigating spaces of future situations. It will take information about a problem, synthesize a model of that problem, and help make decisions based on that model. It will be a valuable tool, but it will not make anyone a god.
That is why, like any other tool, AGI will not be able to make decisions on its own. It will not have goals or agency:
Intelligence is distinct from agency and from goal-setting. If you have intelligence in isolation, all you have is a mechanism for turning information into actionable models. It is not self-directed and has no capacity to define its own goals. Goal-setting has to be an external component that is deliberately added.
In this context, intelligence is like a path-search algorithm. It takes the world model and the goal, both externally provided, and determines the correct sequence of actions required to achieve that goal. Intelligence, in this sense, is about navigating the “space of future situations”. It is, essentially, path-search within that space.
Agency, the pursuit of goals, is what can be dangerous. But that would have to be explicitly built into the system. Constructing that combination is what could create risks:
You could imagine combining an AGI, this “germ” of intelligence, with an autonomous goal-setting system and a value system, effectively turning it into an agent, and then giving it access to the real world. Would that be dangerous? Yes, absolutely. But in that case you would have deliberately designed that danger. It is not an inherent risk of AGI itself; it is something you consciously built.
But AGI will not arrive abruptly, and there should be time to think about those risks:
I think that once we have AGI, we will have plenty of time to anticipate and mitigate this type of risk. AGI will be a powerful technology, and precisely because of that it will be valuable and useful. Anything powerful carries some degree of risk, but we will remain in control because AGI, by itself, cannot define goals. That only changes if you deliberately create an autonomous mechanism for doing so.
We end the article with this optimistic view of the future. A future that Chollet himself now wants to help build more directly than before: on November 14 he announced on X that he was leaving Google to start a company with a friend.
Good luck, François.
See you next time.
-
Perhaps if we train a language model on complete sequences of deductions, the neural network learns to identify patterns used in those deductions and becomes able to generate deductions that may be correct. Something like that is part of what o1 does and also of the new open Chinese model that tries to imitate it, Qwen QwQ. And perhaps a larger model, GPT-5 or GPT-6, will be able to find more complex patterns when trained in a similar way. ↩︎