How does o1 work? (#15 of 2024)
Not great. It seems I am unable to get back to the traditional newsletter format of commenting on what happened over the fortnight. I start writing about one topic and end up getting carried away and turning it into a long article.
Well then, let’s see what comes out. We can always say that the “fifteen days” part refers to the estimated periodicity of these pieces.
Thank you very much for reading.

Strawberry Team: some of the OpenAI researchers responsible for o1.
A first look at o1
On September 12, OpenAI released its new LLM: o1. This is not the expected GPT-5, but a model based on a completely new approach, one that is capable of “reasoning” about problems before answering, and that shows the user the best chain of thought it found to solve the problem at hand.
Let’s begin by commenting on how it works from the point of view of a ChatGPT user. Unlike GPT-4o, the o1 model is available only to paying users; so far they have not enabled a free tier. In fact, running it must be quite expensive for OpenAI, because they have imposed a limit on the number of queries you can make even as a Plus user.
When the user interacts with o1, at first there is no difference in the interface. There is a text field where we can type the question we want to ask. For now, it is not possible to upload any file or image, only text.
Once we ask our question, which we can do in Spanish, and click “send”, the differences begin: the OpenAI icon starts blinking and the phrase “Thinking…” appears.
The model does not return the result instantly. Instead, it generates successive “reflections” until, after quite a few seconds, it produces an answer. We can watch those reflections in real time by expanding the word “Thinking”. If we do that, bold phrases appear with the title of some supposed reflection the model is carrying out, followed by a somewhat longer explanation in the first person. For example:
Simplifying the code
I am thinking about improving fetchChats, simplifying and clarifying how it works while preserving efficiency and readability.
In the following image we can see the chain of thoughts produced by o1 when I asked it to help me with some Swift code I am writing and to simplify a fairly complicated function containing several SQL queries and several iterations over the results:

It seems to analyze in detail all the steps it is taking in the reasoning and to reflect on the result. It even encourages itself: Let’s move forward with this!
Many times these reasonings are “meta-reflections” about the chain of thought itself, as in the following example that someone posted on X, in which o1 explains that “OpenAI’s policies prohibit showing the assistant’s internal reasoning or thought process.” Very curious.

After spending a while “thinking”, the reasoning chain ends and the final answer appears. It is much more elaborate than the answers produced by earlier models such as GPT-4o. It contains many more explanations and considerations, and it gives the impression that it has been thought through carefully and that different factors were considered before reaching a conclusion.
In my own completely subjective experience, when I use o1 as a programming assistant, the result has always been excellent, even with difficult problems and complex code. It has always found a solution to what I asked for and offered valid and reasonable alternatives. Much better than GPT-4o, which was already very good.
As a summary, by observing how o1 behaves we can draw the following conclusions about how it works:
- The model produces an “internal reasoning” made up of thought steps.
- This internal reasoning is monitored, and the user is shown only a summary of it.
- The model uses much more time than earlier models.
- It produces much more elaborate explanations in which you can tell that it has reflected much more deeply on the problem posed.
The first evaluations
The first evaluations show that, beyond my subjective impressions, what OpenAI has presented is a genuinely important advance.
On the Chatbot Arena LLM Leaderboard, o1-preview quickly moved into first place, far ahead of Gemini 1.5, Grok 2, and Claude 3.5 Sonnet.
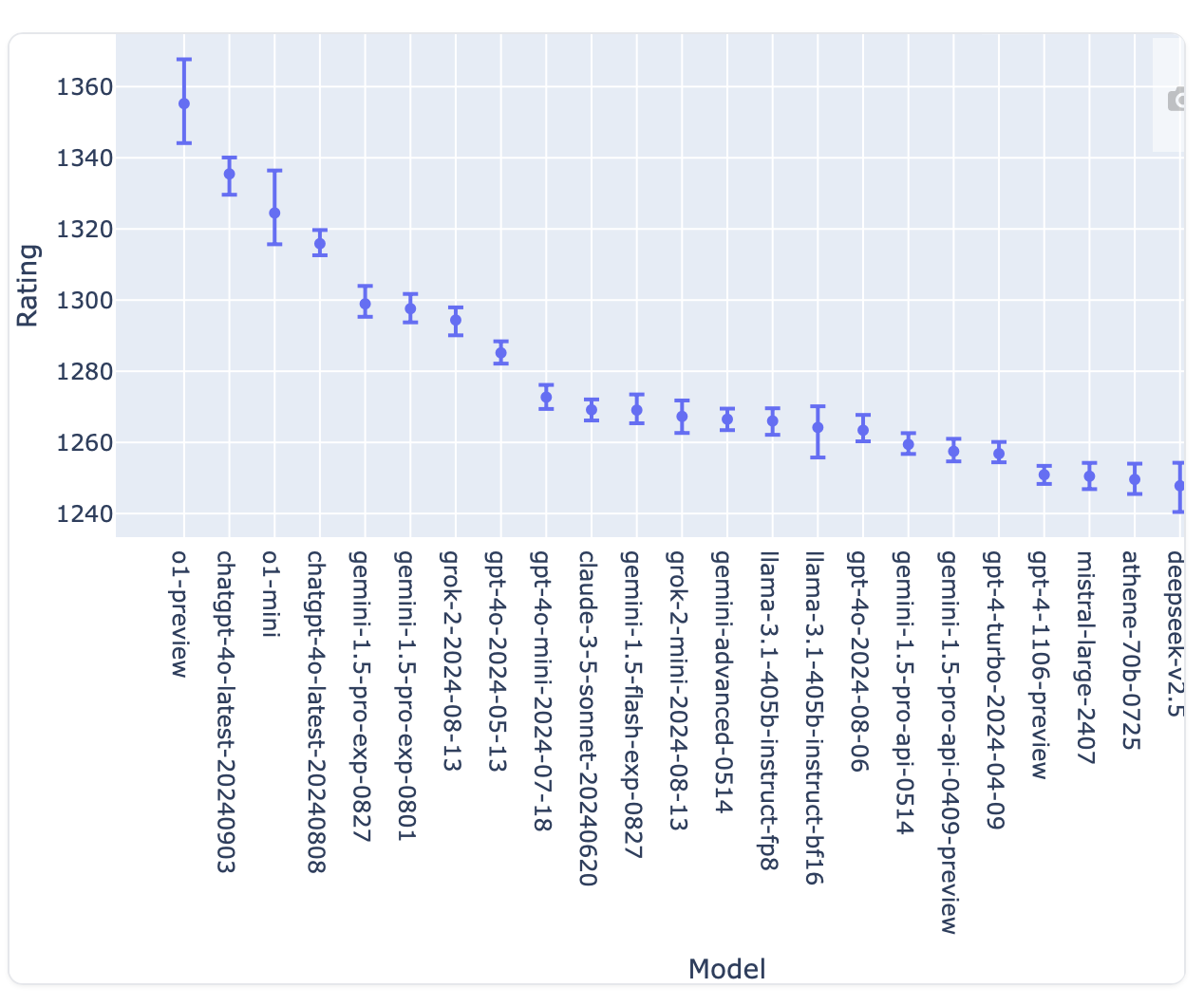
And Professor Subbarao Kambhampati of Arizona State University, who developed an extensive test based on the blocks world to measure the ability of LLMs to plan actions, has published a paper showing that o1-preview reaches success rates of 97%, 41%, and 52% on tasks where the best previous models achieved 62%, 4.3%, and 0.8%. Going from 0.8% to 52% is completely wild.
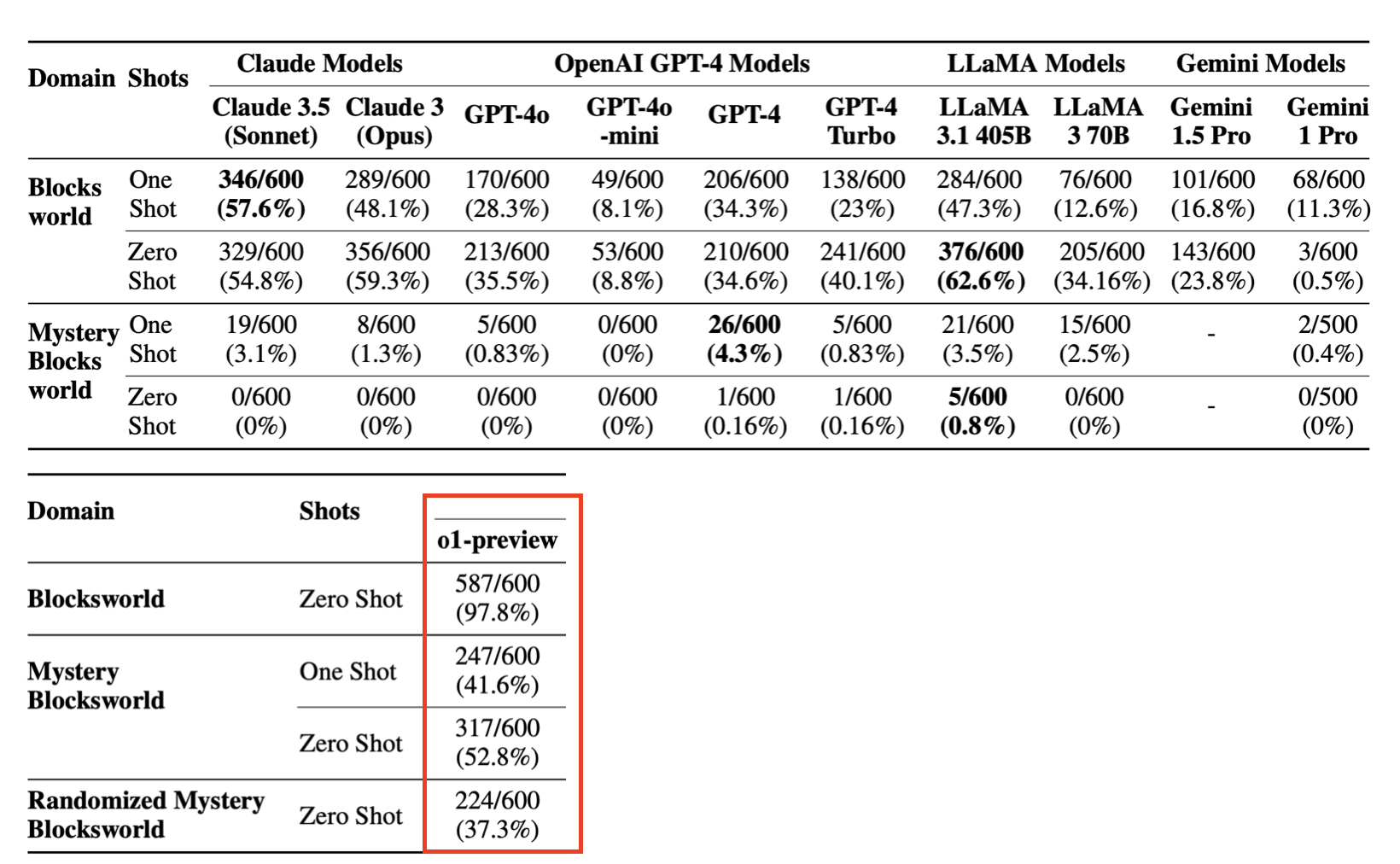
Like any good scientist, Professor Subbarao is not overly effusive, but he ended a thread on X with this tweet:
The o1 model seems to move away from the approximate retrieval nature of LLMs toward something like approximate reasoning.

Approximate reasoning. That is quite relevant, especially coming from someone who has spent a long time arguing, correctly, that LLMs cannot plan.
What OpenAI explains
OpenAI stopped explaining how its models work a while ago. That becomes very clear if we remember the launch of ChatGPT a couple of years ago. Back then, OpenAI’s post linked to a paper titled Training language models to follow instructions with human feedback, which explained in depth the RLHF (Reinforcement Learning from Human Feedback) process that made it possible to build the first version of ChatGPT.
However, for the o1 model all we really have is one post, Learning to Reason with LLMs, where some of the ideas behind the model are presented without much detail. They have also published a list of the people who contributed to the development of o1, a post about o1-mini, and a paper describing the safety tests they performed on o1, the OpenAI o1 System Card.
And there is also a video with a conversation with the leaders of the team that developed o1:
What does OpenAI tell us in these documents and interviews? We can draw some conclusions, reinforced by papers and posts that have been appearing.
1. Reinforcement Learning with Chain-of-Thought (CoT) Reasoning
The first paragraph of OpenAI’s document about o1 includes the phrase Reinforcement Learning with Chain-of-Thought (CoT) Reasoning. To understand that concept better, we need to explain what CoT is and how reinforcement learning is used.
The term CoT, chain of thought, is very common in the field of LLMs. It refers to the prompting technique in which we ask the model to reason step by step before solving a problem. If we make the model generate the reasoning steps needed to solve a problem, it will solve it much more easily than if we ask directly for the solution. Jason Wei, then at Google and now at OpenAI, was in January 2023 the first author of the important paper Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, which introduced CoT with the following figure:
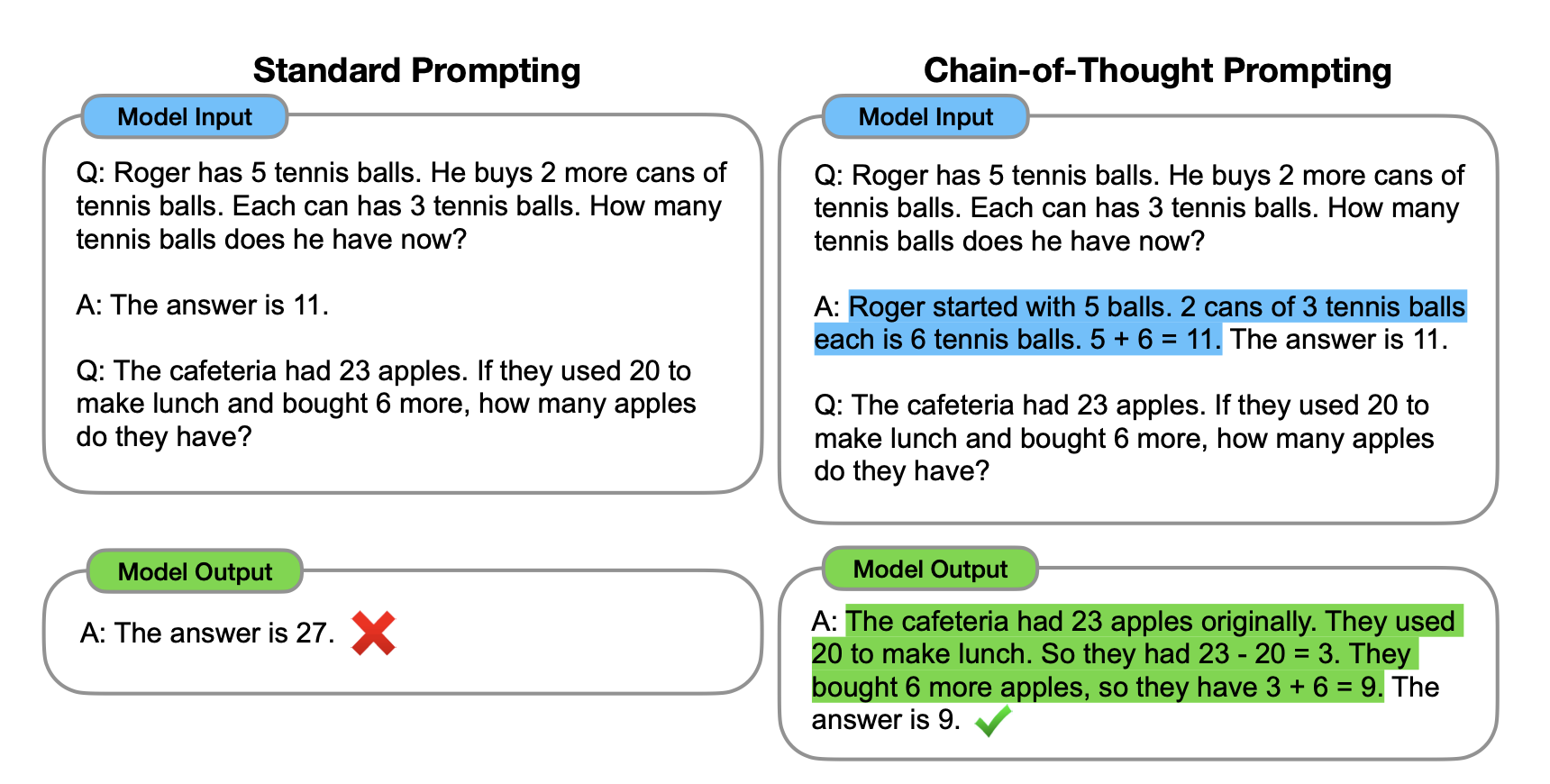
The model’s output is correct when we give it an example of a reasoning chain. Later papers have even shown that it is not necessary to provide those examples or ask for them explicitly in the prompt, because these reasoning chains can be learned from examples.
The other term that appears there is reinforcement learning, RL. This is an older technique that DeepMind applied successfully in AlphaGo and AlphaZero. The algorithm learns what the best action is in each state of the world by efficiently exploring all possible actions across all possible states. Although that sounds simple, when the number of states is exponential, or when the states are difficult to recognize, as with positions on a Go board, the problem becomes extremely complex. That raises the question of how to distinguish the states in which a given action is appropriate and which variables we should look for in those states.
Until AlphaGo, RL had mostly been applied to simple games and toy problems, where the world was clearly specified and involved only a few variables. AlphaGo was one of the first examples showing that much more complicated problems could be solved with this technique. How? By incorporating neural networks that learn to identify the states of a complex world and the possible actions that can be applied in them.
Applying RL to LLMs, where the state of the world is a textual description generated by the user or by the model itself, presents significant challenges. And getting LLMs to learn to use CoT is also a complex task that OpenAI does not detail in its document. However, in the video, Trapit Bansal says the following:
When we think about training a model to reason, the first thing that comes to mind is that we could have humans write out their thought process and train the model on that. The revelatory moment for me was discovering that if we train the model with reinforcement learning to generate and refine its own chain of thoughts, it can do that even better than if humans had written those chains. And the best part is that you could really scale this process.
So it seems that they did train the model on chains of thought written by humans. And, more importantly, they were able to create models, possibly using RL, that generate those chains of thought. According to Karl Cobbe, also in the video, the results have been excellent:
When I was young, I spent a lot of time doing math competitions, and that was basically the reason I got interested in artificial intelligence: I wanted to automate that process. It has been a very special moment for me to watch the model follow steps that are very similar to the ones I used to solve those problems. It is not exactly the same chain of reasoning I would follow, but it is incredibly similar.
That is how they were able to obtain millions of training examples with which they could develop an LLM, o1, that has not only learned to predict the next token of a text, but also the next token in a chain of reasoning.
And on top of that, what people who talk about exponential growth keep pointing out seems to be coming true: we are entering a virtuous circle in which AIs are used to train a new generation of AIs that are even better.
Finally, to be more precise, reinforcement learning was not used only to generate training samples. According to the first paragraph of OpenAI’s Learning to Reason document, it was used to train o1 itself. But they do not explain how.
We introduce OpenAI o1, a new series of frontier models trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers. It can produce a long chain of internal thought before responding to the user.
2. Hidden reasoning
The chains of reasoning generated by the model are hidden from the user and are examined before the final result is shown. During the reasoning process, the user sees only a summary of the reasoning that took place. And any model outputs that do not satisfy the safety guidelines are blocked.
This is mentioned in the System Card as one of o1’s positive features for improving safety, because it increases the transparency and legibility of the system:
In addition to monitoring model outputs, we have long studied the possibility of monitoring their latent thinking. Until now, that latent thinking was available only in the form of activations: large blocks of unreadable numbers from which we could extract only simple concepts. Chains of thought are much more legible by default and could allow us to monitor our models for much more complex behaviors.
The model doing this monitoring could be another model such as GPT-4o, prepared for that task. Or it could be o1 itself. They do not explain any of this either.
3. Better results with more computation
In OpenAI’s post Learning to Reason with LLMs, one of the few images they present is the following:

On the vertical axis we see o1’s score on questions from the American Mathematics Olympiad. The plot on the left shows the typical result we already knew from LLMs, and from neural networks in general: the longer you train them, the better the results. The plot on the right shows something new: the amount of computation time used by the model can be adjusted. And the more time it has, the better the results. In the figure, the same model can go from 20% correct answers to 80% if we give it two orders of magnitude more time, 100 times more.
What is o1 spending that computation time on? Given that the rate at which LLMs generate a response is roughly constant, the simplest answer is that it uses the time to generate many responses. The more time it has, the more responses it generates. And somehow, from that whole set of generated responses, a final answer is built, or selected, and that is the one shown to the user.
Denny Zhou is a DeepMind scientist who leads a team researching reasoning in LLMs. He recently took part in the Large Language Model Agents course with a very interesting talk titled LLM Reasoning. In one of the slides from the talk, he presents an equation that gives the theoretical basis for how to obtain the best solution:

The “P"s in the formula represent the probabilities of the tokens and responses produced by the model. They are, roughly speaking, the scores associated with each response. The higher the probability, the better the score of that chain of reasoning or answer. We should therefore keep the final answer that maximizes the sum of the scores of the reasoning chains that end up producing that answer. To simplify, if we assume that all the reasoning chains generated by the LLM have the same probability and that the LLM generates n reasoning chains, then we should keep the final answer that appears as the outcome of the greatest number of reasoning chains.
The important point in the equation is that obtaining the best final answer is based on generating many responses and keeping the best one. The more computation time we have, the more responses the LLM can generate, and the better the answer we obtain will be.
The future
What does all of this tell us about how LLM technology is going to evolve? Will Google and Meta follow this trend and make models based on CoT? Or will the new models they present continue to rely on scaling the existing ones? Will OpenAI release a generic GPT-5 and then a more advanced o2?
We do not know. What does seem increasingly clear is that the transformer technique is still working and that LLMs are going to become ever more powerful and general.
After presenting o1, Sam Altman wrote a post titled The Intelligence Age in which he says:
In three words: deep learning worked. Humanity discovered an algorithm that can really, truly learn any distribution of data (or really the underlying “rules” that produce any distribution of data). Astonishingly, the more compute and data we feed it, the better it gets at helping people solve hard problems. I find this hard to really understand no matter how much time I spend thinking about it.
A recent talk by Hyung Won Chung, an OpenAI researcher, explains the need to go beyond predicting the next word. And it argues that this is going to be possible with o1.
The learning paradigm based on predicting the next word was only the first step, the way to bootstrap the construction of new, more advanced models. Now that efficient and capable models exist, in the style of GPT-4o mini, it becomes possible to design more complex evaluation functions that go beyond checking whether the model produced the correct word. It is more than possible that these models are currently being used not only to generate training data but also to evaluate the pre-training and fine-tuning of future models.
And we should not dismiss the power of next-word prediction just yet. As Karpathy recently said on X:
As the stack of language models (LLMs) becomes increasingly mature, we may see a convergence of a large number of problems into this modeling paradigm. That is, the problem gets reduced to “next token prediction” with an LLM; the only thing that changes is the use or the meaning of the tokens in each domain.
That is, the “L” in LLMs is irrelevant. We can make the token sequences be anything at all, and the model still keeps learning and generalizing. For example, they are even capable of predicting sequences of data from chaotic systems or protein structure.

Image from the paper “Zero-shot forecasting of chaotic systems”, by Yuanzhao Zhang and William Gilpin, published on arXiv on September 24, 2024.
Everything therefore seems to indicate that we are still not at the end of the curve and that in the coming years many improvements still await us, improvements that will make the models more reliable and more capable and bring us ever closer to AGI.
One final piece of advice, in three words, Altman style: don’t sell NVIDIA. Or, if you do not own stock in the company, there is still time to buy.
Addendum
I asked GPT-4o and o1 to summarize the article in one paragraph. This was the result.
GPT-4o:
OpenAI’s new o1 model, released on September 12, introduces an innovative approach by using deep reasoning based on a chain of thought to solve problems, marking a significant leap over previous models. Unlike GPT-4, o1 shows the user its internal reflections before giving a final answer, which is more detailed and more carefully considered. Although it is available only to paying users and comes with a query limit, its reasoning ability has surpassed other models in evaluations, obtaining surprising results on complex tasks.
o1:
OpenAI has released o1, a new language model that introduces an innovative approach by “reasoning” before answering and generating a chain of thought that is summarized to the user during the process. Although the user interface is similar to previous versions, o1 includes a waiting period in which the model elaborates and shows summaries of its reflections in real time, producing more elaborate and more accurate answers, especially on complex tasks such as programming. The initial evaluations place o1 as the performance leader, significantly outperforming other models and showing notable advances in reasoning and planning. OpenAI has been reserved about the technical details, but it is known that o1 uses “Reinforcement Learning with Chain-of-Thought Reasoning”, training with reasoning chains generated and refined by the model itself. This advance suggests a promising future for language models, with continued improvements in both capability and efficiency.
o1’s summary is much better and more detailed, although it did not like the mention of NVIDIA:

Until the next fortnight.